
안녕하세요! 코딩하는 경제학도 쏘코입니다.
드디어 이번 포스팅이 알고리즘분석의 마지막 포스팅이 될 것 같습니다. 참 길었습니다 ㅠㅠ
이번 포스팅에서는 해시와 문자열 매칭으로 검색을 구현하는 방법에 대해 알아보도록 하겠습니다.
목차
0. 해싱
만약 키가 주민등록번호라면 해당 번호의 저장소 를 모두 만들기는 굉장히 어렵습니다. 13자리의 숫자를 담아야 하기 때문입니다.
그렇다면 어떻게 효율적으로 인덱스를 관리할 수 있을까요?
이럴 때 사용할 수 있는 방법이 바로 해싱입니다.
0부터 99의 인덱스를 가진 크기가 100인 배열을 만든 후에, 키를 0~99 사이의 값을 가지도록 해시(hash)합니다. 여기서 해시함수는 키를 배열 인덱스값으로 변환하는 함수입니다.
예를 들면 h(key) = key % 100 으로 나타낼 수 있습니다.

만약 100개의 키가 있고, 이들이 모두 다른 해시값을 가질 확률(100개의 데이터가 모두 다른 방에 저장될 확률)은 100!/100^100입니다. 굉장히 작죠?
위에서 계산한 무지 낮은 확률 이외에는 2개 이상의 키가 같은 해시값을 갖게 됩니다.
간단히 말해 충돌(collision)이 발생하게 되는 것이죠.
충돌을 막기 위해서 사용하는 방법으로는 open hashing과 closed hashing이 있습니다.
open hashing의 경우 hash값을 head로 갖는 데이터 블록을 사용합니다.
각 hash값을 가지는 경우 맞는 head에 연속적으로 매달리게 됩니다.
closed hashing의 경우 배열 내에 데이터를 저장합니다.
배열의 개수는 한정되어 있으므로 데이터를 저장할 때 겹치는 데이터가 있는 경우 옆으로 이동하거나 몇 칸을 더 벌려서 저장하는 등의 방법을 사용합니다.

open hashing의 경우 linked list와 비슷한 형태로 저장되기 때문에 충돌이 일어날 가능성은 거의 없으나 해싱이 효율적으로 작동하기 위해서는 키가 바구니에 균일하게 분포되어야 합니다.
n개의 키와 m개의 바구니가 있을 때 각 바구니에 평균적으로 n/m개의 키를 갖게 하면 됩니다.
이 말은 n개의 키가 m개의 바구니에 균일하게 분포되어 있다면 검색에 실패한 경우 비교 횟수는 n/m이라는 것으로 연결됩니다.
또한 n개의 키가 m개의 바구니에 균일하게 분포되어 있고, 각 키가 검색하게 될 확률이 모두 같다면 검색에 성공한 경우 비교 횟수는 n/2m + 1/2이 됩니다.
검색에 성공한 경우 비교 횟수에 대한 증명을 해보겠습니다.
각 바구니의 평균 검색시간은 n/m개의 키를 순차검색하는 평균시간과 같습니다. (한 바구니에 n/m개의 키를 담고 있을 테니까요!!)
x개의 키를 순차검색하는데 걸리는 평균 검색시간은 1*(1/x)+2*(1/x)+...+x(1/x)가 됩니다. (당연히 모든 바구니에 접근할 확률은 같다는 것을 전제로 합니다)
이걸 정리하면 (x+1)/2가 되고, n/m를 그대로 x에 대입하면 (n/m + 1) / 2 = n/2m + 1/2가 됩니다.


closed hashing의 경우 특정 bucket 내에만 데이터에 저장되기 때문에 충돌을 피하기 어렵습니다.
이런 경우에 대비해서 linear probing, quadratic probing, double hashing 등 다양한 방법을 사용합니다.
위 방법들에 대해서 간단하게 알아봅시다.
먼저 k를 key, m을 hash table의 크기라고 가정합니다.

linear probing의 경우 충돌 시 오른쪽으로 이동하면서 빈칸에 저장합니다.
h(i,k) = ( h(k) + i ) mod m, i = 0,1,2,3,... (mod는 나머지 연산입니다)

quadratic probing의 경우 오른쪽으로 이동하는데, linear의 경우와 다르게 기하급수적으로 이동합니다.
h(i,k) = ( h(k) + i^2 ) mod m, i = 0,1,2,3,...

double hashing의 경우 또 다른 하나의 해시함수를 만들어서 구분하는 방법입니다.
h(i,k) = ( h_1(k) + i * h_2(k) ) mod m, i = 0,1,2,3,...

다만 알아두어야 할 점은 위 방법들의 공통적인 문제점은 자료가 삭제될 경우 문제가 발생할 수 있다는 것입니다.
그렇기 때문에 데이터를 삭제하더라도 다음 데이터의 위치에 접근할 수 있는 추가적인 정보가 남아있어야만 합니다.

m개의 메모리가 있다고 할 때 단순한 형태의 해쉬함수를 만들어보면
h(k) = k mod m 같은 형식으로 만들 수 있습니다.
여기서 m은 보통 2의 지수배가 아닌 소수(prime number)를 사용하는 것이 일반적입니다.
2의 지수배, 혹은 10의 지수배의 경우 해싱을 통한 암호화 효과가 낮기 때문입니다.
예를 들어서 다음과 같은 조건에서 해시함수를 만든다면
- n=2000
- 데이터 하나는 8bits
- chaining 방법 사용(open hashing방법과 같이 연결 리스트를 사용하는 것을 chaining이라고 부릅니다!)
- 평균 3번의 unsuccessful search를 감수(검색 횟수의 평균을 3번으로 만들고 싶다는 말과 같습니다!)
a = 2000/3, m = 701(a에 가까우면서 2의 지수배에 가깝지 않은 소수)
h(k) = k mod 701
과 같은 방식으로 해시함수를 만들 수 있습니다.
아래는 closed hashing을 구현한 파이썬 코드입니다. (충돌은 고려하지 않았습니다)
# closed hashing
M=10
# ord를 이용해 아스키코드로 바꾼다
# 충돌사항은 고려하지 않음
def hashing(data):
hash_data =[-1 for i in range(0,M)] # M개만큼 -1를 담은 hash_data 리스트를 만든다
for d in data: # 데이터들을 하나씩 뽑아서 d에 넣는다
s = 0
for x in d: # 뽑아낸 데이터를 한 글자씩 뽑아서 x에 넣는다
s += ord(x) # x의 아스키코드값을 s에 더해준다
s = s%M # 다 더해준 s를 M으로 나눈 나머지를 s에 저장한다
hash_data[s]=d # hash_data의 s번째 index에 그 데이터를 넣는다
return hash_data
data =["abc", "name", "school", "KHU"]
print(hashing(data))
1. 선택문제
1.0. 최대키와 최소키
선택문제는 n개의 키 중 k번째로 큰(작은) 키를 찾는 문제입니다.
일반적인 선택문제에서는 키가 따로 정렬이 되어 있지 않다고 가정합니다.
먼저 최대키를 찾는 경우를 생각해보겠습니다. (최소키는 최대키와 동일한 방법이기 때문에 생략합니다.)
앞에서부터 하나씩 확인하면서 최대값을 갱신해 주는 방식으로 찾을 수 있습니다.
T(n) = n-1이 되는데, 키 비교만 수행하여 가능한 모든 입력 n개 중에서 최대키를 찾을 수 있는 결정적 알고리즘은 어떤 경우에도 반드시 최소한 n-1번의 비교가 필요합니다. (정렬이 되어있지 않기 때문입니다.)
최대키를 찾는 경우의 수도코드와 파이썬 코드입니다.

# 최대키 찾기
def find_largest(n, s):
large = s[0]
for i in range(1,n):
if s[i] > large:
large = s[i]
return large
s = [1,5,3,9,7]
n = len(s)
print(find_largest(n,s))
이번에는 최소키와 최대키를 동시에 찾는 방법입니다.
위와 같은 방식으로 찾는다고 하면 최대 2(n-1)번의 비교로 찾을 수 있습니다.
수도코드대로 만든다면 s[0]이 가장 작은 값이 되는 경우가 최악의 케이스가 되겠네요. (if문과 elif문이 모두 돌기 때문입니다!)
아래는 최대키와 최소키를 동시에 찾는 수도코드와 파이썬 코드입니다.

# 최대키와 최소키 동시에 찾기
def find_both(n, s):
small = s[0]
large = s[0]
for i in range(1,n):
if s[i] < small:
small = s[i]
elif s[i] > large:
large = s[i]
return small, large
s = [1,5,3,9,7]
n = len(s)
print(find_both(n,s))
똑같이 최대키와 최소키를 찾는데, 더 효율적으로 찾을 수는 없을까요?
키를 짝지어서 비교하는 방법으로 데이터의 비교 횟수를 줄일 수 있습니다.
2개씩 비교해서 큰 요소와 작은 요소를 구분합니다.
그리고 큰 요소들 중에서 가장 큰 요소를 찾고, 그 다음엔 작은 요소들 중에서 가장 작은 요소를 찾습니다.
이 방법을 사용하면 처음 비교에서 n/2, 최대키를 찾는데 n/2-1, 최소키를 찾는데 n/2-1 만큼의 시간이 들어서 총 O(3n/2) 시간이 소요됩니다. 이전의 O(2n-1)보다는 확실히 줄어든 모습을 볼 수 있습니다.

아래는 키를 짝지어서 최소키와 최대키를 찾는 수도코드와 파이썬 코드입니다.
수도코드는 짝수인 경우에만 정상적으로 작동하지만 파이썬 코드에서는 홀수인 경우에도 정상적으로 돌아갈 수 있도록 조건문을 추가하였습니다.

# 키를 짝지어서 최대키와 최소키를 동시에 찾기
def find_both2t(n,s):
if s[0] < s[1]: # 초기값 정리
small = s[0]
large = s[1]
else:
small = s[1]
large = s[0]
for i in range(2,n-1,2): # 2칸씩 넘어가면서 비교
if s[i] < s[i+1]:
if s[i] < small:
small = s[i]
if s[i+1] > large:
large = s[i+1]
else:
if s[i+1] < small:
small = s[i+1]
if s[i] > large:
large = s[i]
if n%2 == 1: # n이 홀수인 경우 마지막 값까지 확인하기 위한 조건문
if s[n-1] < small:
small = s[n-1]
if s[n-1] > large:
large = s[n-1]
return small, large
s = [1,5,3,9,7]
n = len(s)
print(find_both2t(n,s))
이렇게 키를 비교해서 n개의 키 가운데 최소키와 최대키를 모두 찾을 수 있는 결정적 알고리즘은 최악의 경우 n이 짝수인 경우는 3n/2 - 2, n이 홀수인 경우는 3n/2 - 3/2만큼의 비교를 수행해야 합니다.

1.1. 차대키
차대키는 두 번째로 큰 키입니다.
차대키를 찾는 방법은 여러 가지가 있을 수 있습니다.
첫 번째 방법은 먼저 최대키를 찾고(n-1회 비교) 다음 최대키를 찾으면(n-2회 비교) 됩니다.
이 방법의 경우 총 2n-3번의 비교가 필요합니다.
두 번째 방법으로는 토너먼트 방법이 있습니다.
토너먼트를 시행하여 최대 우승자가 최대키이고, 각 시합에서 진 팀을 이긴 팀의 리스트로 만듭니다.
우승팀의 리스트에서 최대값을 찾으면 차대키가 됩니다.
짝지어서 최대값을 구하는 방법과 유사합니다.

총 시합의 횟수는 1라운드에는 n/2, 2라운드에는 n/2^2, 3라운드에는 n/2^3 ... 이런 식으로 진행됩니다.
그리고 라운드는 lg n이 됩니다.
따라서 총 시합 횟수는 n-1이 됩니다.

이제 우승자의 리스트는 lg n개의 데이터를 가지고 있습니다.
이 말은 우승자의 리스트에서 최대키를 찾는 데에는 lg n - 1 이라는 시간이 걸리게 되는 것이죠.
즉 차대키를 찾는 전체 과정의 T(n)은 n-1 + lg n - 1 = n + lg n - 2가 됩니다.
정리하면 키를 비교해서 n개의 키 가운데 차대키를 모두 찾을 수 있는 결정적 알고리즘은 최악의 경우 n + ceil(lg n) - 2번의 비교를 수행햐아 합니다.
아래는 차대키를 구하는 파이썬 코드입니다.
# 차대키 찾기
s=[2,6,4,8,10,3,7,1]
a = {} # dictionary형태
while(len(s)>1):
t=list()
for i in range(0,len(s),2):
if s[i] > s[i+1]:
if s[i] not in a: # 초기화할 때 딕셔너리 안에 리스트 형태로 넣어주기 위해서
a[s[i]] = [s[i+1]]
else: # 한번 리스트로 생성되었으면 append로 요소 추가
a[s[i]].append(s[i+1])
t.append(s[i])
else:
if s[i+1] not in a: # 초기화할 때 딕셔너리 안에 리스트 형태로 넣어주기 위해서
a[s[i+1]] = [s[i]]
else: # 한번 리스트로 생성되었으면 append로 요소 추가
a[s[i+1]].append(s[i])
t.append(s[i+1])
s = t[:] # s를 t로 갱신
print(a)
print(s)
winner = t[:]
print(winner[0])
print(a[winner[0]])
print("second =", max(a[winner[0]]))

1.2. k번째 작은 키 찾기
위에서 최대키, 최소키, 차대키 등 특별한 키를 찾는 방법에 대해서 알아봤다면
이번에는 일반화하여 k번째로 작은 키를 찾는 방법에 대해서 알아보겠습니다.
방법은 단순 방법, partition 방법, O(n) 방법 총 3가지로 나눌 수 있습니다.
첫 번째 방법인 단순 방법은 정렬 후 k번째를 선택하는 것입니다.
이 방법의 경우 정렬의 시간복잡도인 O(n lg n)이 걸리게 됩니다.
두 번째 방법인 partition 방법은 퀵정렬(Quick sort)의 partition을 사용하는 방법입니다.
퀵정렬에서 피벗을 기준으로 작은 요소들과 큰 요소들로 나눴는데, 이것이 partition입니다.
k를 알고 있다면 작은 요소들, 큰 요소들, 그리고 피벗 중에서 k가 어느 위치에 위치할 지도 알게 됩니다.
이 방법은 최악의 경우 n(n-1)/2번의 비교를 하게 되고, 평균적으로 O(3n)번의 비교를 하게 됩니다.
아래 예시를 보겠습니다.
만약 우리가 4번째로 큰 요소를 찾아야 한다면 45보다 작은 요소들을 담은 리스트에서 값을 찾으면 되고,
8번째로 큰 요소를 찾아야 한다면 45보다 큰 요소를 담은 리스트에서 값을 찾으면 됩니다.
이것을 재귀적으로 진행하면 partition 방법이 되는 거죠!

아래는 partition 방법의 수도코드와 파이썬 코드입니다.
퀵정렬과 거의 유사하기 때문에 헷갈리시는 부분은 이전 포스팅의 퀵정렬을 보시면 이해에 도움이 될 수 있습니다.


# partition 방법 (퀵정렬과 유사)
def selection(low, high, k):
pivotpoint = -1 # 사용 전에 미리 변수를 만들어놓기
if low == high:
return s[low]
else:
pivotpoint = partition(low, high, pivotpoint)
if k == pivotpoint:
return s[pivotpoint]
elif k < pivotpoint:
return selection(low, pivotpoint-1, k)
else:
return selection(pivotpoint+1, high, k)
def partition(low,high,pivotpoint):
pivotitem = s[low]
j = low
for i in range(low+1, high+1):
if s[i] < pivotitem:
j += 1
s[i], s[j] = s[j], s[i]
pivotpoint = j
s[low], s[pivotpoint] = s[pivotpoint], s[low]
return pivotpoint
s = [3,1,5,4,2]
n = len(s)
print(selection(0,n-1,1))
selection(1,n,k)의 시간복잡도는 최악의 경우 W(n) = n(n-1)/2, 최고의 경우 B(n) = 2n, 평균은 대략 A(n) = 3n 입니다.
최악의 경우는 데이터를 피벗으로 쪼갤 때 한쪽으로 쏠리는 경우이고, 최고의 경우는 데이터를 피벗으로 쪼갤 때 정확히 반반으로 쪼개지는 경우입니다.

마지막 세 번째 방법은 O(n) 방법입니다.
간단하게 말하면 퀵정렬의 업그레이드버전이라고 볼 수 있습니다.
데이터를 5개의 묶음으로 나누고, 중앙값들을 모아서 숫자 하나를 고른 후에 고른 숫자보다 작은 그룹, 고른 숫자만 있는 그룹, 고른 숫자보다 큰 그룹을 나누고 k와 인덱스들을 비교해서 재귀를 돌리거나 값을 가져오는 알고리즘입니다.
퀵소트의 pivotpoint가 여기서는 묶음의 가운데 값들 중에서 랜덤한 값이 되는 것이죠.
partition 방법과의 차이라면 중앙값들 중에서 pivotpoint가 뽑히는 것이기 때문에 최악의 케이스에도 O(n)을 만족할 수 있다는 점입니다.
아래 수도코드를 바탕으로 시간복잡도를 계산해보면, 먼저 5개로 각각 나눈 요소들을 정렬하는데에는 최대 4! * ceil(n/5)만큼의 시간이 걸립니다. 상수 * n/5 이기 때문에 O(n)이 나오게 됩니다.
그 다음 5개로 각각 나눈 것들에서 재귀로 중앙값을 뽑아내는 데에는 T(n/5)시간이 걸립니다. 원래 SELECT함수가 T(n)시간이 걸리는데, 데이터의 양이 1/5로 줄었으니 당연히 T(n/5)가 되겠죠?
그 아래에서는 중앙값과 S1, S2, S3 데이터들을 비교하는데에 O(n)이 걸립니다. 하나씩 가져와서 비교하는 것이니 당연히 n번이면 끝납니다.
마지막으로 k가 S1에 위치하는지, S2에 위치하는지, S3에 위치하는지에 따라 값을 도출하거나 다시 영역 내에서 재귀함수를 돌리게 됩니다. 여기서 T(3n/4)가 걸립니다. 이 부분은 아래에서 추가로 설명하겠습니다.
결과적으로 T(n) <= T(n/5) + T(3n/4) + cn 이기 때문에 O(n)시간이 걸리게 됩니다. 이 부분도 아래에서 더 자세히 설명하겠습니다.



T(3n/4)가 나오는 재귀함수 부분에 대해 추가적으로 설명드리겠습니다.
위 방식대로 m을 뽑으면 중앙값의 중앙값(median of median)이 나오게 됩니다. m을 구할 때도 재귀함수를 썼으니까요!
실제로 정렬을 한 것은 아니지만 편의상 정렬을 했다고 가정합니다.
m은 중앙값의 중앙값이기 때문에 정렬을 했다고 했을 때 정가운데에 위치하게 됩니다.
그리고 m을 기준으로 왼쪽 위, 노란색 영역은 확실히 m과 같거나 작은 영역이 되고, m을 기준으로 오른쪽 아래, 살구색 영역은 확실히 m과 같거나 큰 영역입니다. (5개씩 나눠서 정렬했기 때문입니다.)
그 외의 나머지 색칠 안된 영역은 m보다 클 지 작을 지 여부를 알 수 없는 영역입니다.

M 중에서 적어도 floor(n/10)개의 원소가 m보다 크거나 같습니다. M이 n/5개 있고, 그 중에서 절반은 m보다 크거나 같으니까요!
이들 각 원소에 대해 S(원래 리스트)중에서 적어도 2개의 원소가 그 값보다 큰 원소가 존재합니다. (5개씩 나눠서 sort까지 했으니까요!)
n >= 50에서 S1의 크기는 최대 n - 3 * floor(n/10)이 됩니다. 3 * floor(n/10)은 노란색 혹은 살구색 영역이 됩니다.
그리고 n - 3 * floor(n/10)의 값은 3n/4보다 작습니다. 그렇기 때문에 T(3n/4)라고 표기한 것입니다. (T(7cn/10)이라고 표기해도 동일합니다)
SELECT 함수 내에서는 O(n)으로 빠져나가거나, 상수배의 더 좁은 범위의 재귀함수로 돌아가는 경우밖에 없으므로, SELECT 함수의 시간복잡도는 결과적으로 O(n)이 됩니다.
마지막으로 정리하면 selection 함수는 단순 partition을 사용하여 임의의 pivot item을 선정했다면, select 함수는 median of median 방법으로 한 쪽의 데이터 개수를 3n/4으로 한정시켰기 때문에 최악의 케이스를 조금 더 잘 대처할 수 있습니다.

파이썬으로 O(n) 방법을 구현했습니다. insertion_sort가 아닌 다른 sort방법을 사용하셔도 무방합니다.
# O(n) 방법
def insertion_sort(s):
for i in range (1,len(s)):
x = s[i]
j = i-1 # j는 i보다는 작은 인덱스값
# i보다 작은 인덱스값은 이미 정렬이 되어있다
# 정렬이 되어있는 값 중 가장 큰 값부터 순서대로 비교
while j>=0 and s[j]>x: # j가 0보다 크거나 같고 s[i]가 s[j]보다 작으면
s[j+1] = s[j] # 한 칸씩 앞으로 땡기기
j -= 1
s[j+1] = x # 자기자리를 찾으면 그곳에 저장해둔 s[i]를 넣는다
return s
def select(k,s):
tempList=5*[0]
mList =[]
s1=[]
s2=[]
s3=[]
if len(s) < 50: # 길이가 50 미만이면 그냥 정렬해서 찾는다
insertion_sort(s)
return s[k-1]
else:
for j in range(0,int(len(s)/5)):
for p in range(0,5): # 최대 5개의 요소를 가지도록 쪼개서
tempList[p]=s[j*5+p]
tempList = insertion_sort(tempList) # 정렬 후
mList.append(tempList[2]) # median값 삽입
insertion_sort(mList) # median 정렬
m = select( int(len(mList)/2),mList) # 재
for i in range(0,len(s)):
if s[i]< m:
s1.append(s[i])
elif s[i]== m:
s2.append(s[i])
else:
s3.append(s[i])
if len(s1) >= k:
return select(k,s1)
elif len(s1)+len(s2) >= k:
return m
else:
return select(k-len(s1)-len(s2), s3)
N=125 # 간단히 하기 위해 N은 5의 배수로 설정
s=N*[0]
k=120
for i in range(0,N):
s[i]=random.randint(1,1000)
print()
print("original")
print(s)
print()
print(k,"th element = ", select(k,s))
print()
print("sorted")
print(insertion_sort(s))
2. 문자열 매칭
문자열 매칭은 입력 문자열에서 패턴을 찾는 문제입니다.
패턴을 찾는 방법에는 총 4가지가 있습니다.
- 원시적인 매칭 방법
- 오토마타를 이용한 방법
- Rabin-Karp 알고리즘
- Boyer-Moore 알고리즘
각 알고리즘을 하나씩 뜯어보면서 분석해보도록 하겠습니다!

2.0. 원시적인 매칭 방법
말 그대로 원시적입니다.
한 칸씩 땡겨가면서 매칭하는 것이죠. 별 거 없습니다.

시간복잡도는 for문에서 n-m+1번 반복하고, if문에서 m개의 글자를 비교해야 하기 때문에 O(mn)이 됩니다.

원시적인 매칭방법의 수도코드를 파이썬으로 구현하였습니다.
# 원시적인 매칭방법
def naiveMatching(A,p):
n = len(A)
m = len(p)
for i in range(n-m+1):
if p[:m] == A[i:i+m]:
return i # 찾으면 시작 인덱스 반환
return -1 # 못찾으면 -1 반환
A = "tbafgboatgd"
p = "boat"
print(naiveMatching(A,p))
2.1. 오토마타를 이용한 방법
컴파일러 과목을 배우면 그 안에서 오토마타를 배우게 됩니다. (저는 배우지 않았습니다만..)
오토마타 방법은 어휘분석에 쓰이는 상태 전이 함수 델타를 이용한 방법입니다.
우리가 프로그램을 작성하게 되면 첫 번째로 어휘분석, 즉 토큰을 잘라내고 심볼을 구분하는 단계를 거치게 되는데 이 때 구동하는 프로그램에서 상태 전이 함수가 돌면서 패턴을 찾아서 인식합니다.
어휘가 사용자 변수인지, 예약어인지, 숫자인지 등을 구분해내는 것이 어휘분석단계입니다.
그 내부는 state transition diagram을 이용해서 하나하나 정의하게 됩니다.
idenfitier같은 경우 시작할 때 S 상태에서 letter가 들어오면 A라는 상태로 바뀌게 되는데, 그 상태에서 letter나 digit(숫자)이 들어오면 계속 그 상태를 유지하게 됩니다.
계속 반복하다가 적절한 입력이 들어오지 않았다면 올바르지 않다고 인식하게 됩니다.

오토마타 방법을 나타낸 의사코드입니다.
i가 1부터 n까지 움직이면서 상태 전이 함수를 거쳐서 나온 결과 q가 final state와 같으면 발견된 것이고, 그렇지 않으면 다음 칸으로 이동해서 상태 전이 함수를 거치고..를 반복합니다.
이 알고리즘은 시작 후 끝까지 한번에 이어지기 때문에 시간복잡도는 O(n)이 됩니다.

조금 어려울 수 있어서, 정수와 실수를 인식하는 상태 전이도를 예로 들겠습니다.
정수의 경우 10진수, 8진수, 16진수를 파악하고, 실수의 경우 소숫점 유무, 지수표기법 유무를 파악할 수 있습니다.
내용까지 다 이해할 필요는 없지만, 이런 방식으로 패턴을 찾을 수 있다는 것을 이해하면 됩니다.


2.2 Rabin-Karp 알고리즘
Rabin-Karp 알고리즘은 문자열 패턴을 수치로 바꿔 수치 비교를 통해 패턴을 찾는 알고리즘입니다.
보통은 이 수치를 해싱 기법을 이용하여 구합니다. (해싱은 이번 포스팅 맨 위에서 배운 적이 있죠? ^^)
8561이라는 문자를 숫자형태로 바꿔주기 위해서 10의 배수를 곱해주는 것이 Rabin-Karp 알고리즘의 대표적인 예입니다.

찾고자 하는 문자열을 숫자 형태로 바꾸는데는 O(m)이 필요합니다.
m개의 문자열을 가져와서 서로 곱해주고 더해주고 해야하니까요. (해싱 작업!!)
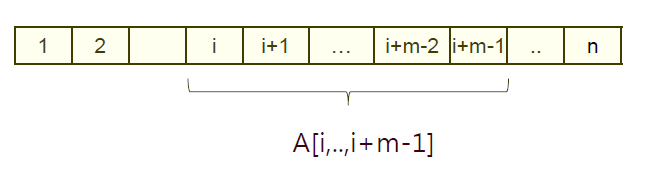
이제 A문자열에서 a문자열의 길이만큼 뽑아서 해싱 작업을 해줍니다.
값이 같다면 매우 높은 확률로 일치하는 문자열일 것입니다. (매우 높은 확률이라는 것은 해싱 기법의 특성상 우연치 않게 값이 같아서 충돌이 일어날 수 있기 때문입니다.)
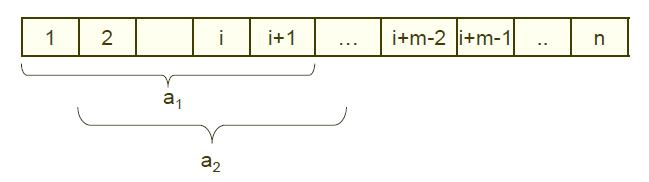
이렇게 계산을 하다보면 계산이 너무 긴 경우가 발생할 수 있습니다.
하지만 매번 모든 계산을 해야 하는 것은 아닙니다.
이전 요소를 이용해서 현재 요소의 계산을 편하게 할 수 있습니다.
만약 위에서 사용했던 방법대로 10의 지수배를 이용하여 계산을 한 경우 이전 값에서 (10^(m-1))*맨 앞의 값 을 빼고 10을 곱해준 후에 현재 요소의 맨 뒤의 값을 더해주면 현재 요소의 값을 구할 수 있습니다.
이 방식을 사용하면 곱셈 2회, 덧셈 2회만으로 a값을 계산할 수 있습니다. (시간복잡도는 O(n))
하지만 계산값이 너무 커질 수 있다는 문제점이 있습니다.

약간의 개선을 한 RabinKarp 함수의 수도코드입니다. d는 진수를 의미합니다. (10진수가 아니어도 사용이 가능합니다!)

계산값이 너무 커지는 문제점을 방지하기 위해서 mod 함수를 사용할 수 있습니다.
보통 나머지를 만들어내는 나누는 수 q는 소수(prime number)가 오고, d(진수)*q가 컴퓨터가 처리할 수 있는 범위가 되도록 q를 설정합니다.
그리고 a_i 대신 b_i = a_i mod q를 사용합니다.

mod 함수를 이용하여 개선한 RabinKarp 함수의 수도코드입니다.
mod연산을 했기 때문에 높아진 충돌 가능성에 대한 추가적인 검증으로 실제로 매칭되는지를 확인합니다.

2.3. Boyer-Moore 알고리즘
여기서는 Boyer-Moore 알고리즘의 약식 형태인 Boyer-Moore-Horspool 알고리즘을 공부하도록 하겠습니다.
더 어려운거 아니냐구요? 약식 형태인만큼 훨씬 간소화되어서 이해하기 쉬운 알고리즘입니다.
Boyer-Moore-Horspool 알고리즘의 핵심은 string에서 건너뛸 수 있는 만큼은 모두 건너 뛰는 것입니다.
아래 그림을 보면 원시적인 매칭방법과의 차이를 바로 알 수 있습니다.
맨 처음에는 (1)을 비교합니다. 원시적인 매칭방법이라면 다음에 (2)로 넘어가겠죠?
하지만 Boyer-Moore-Horspool 알고리즘이라면 (3)으로 바로 넘어갑니다.
4번째에 있는 h라는 글자가 찾고자하는 글자에 패턴에 없기 때문입니다.
만약 패턴이 show라면 (4)에서 비교한 후 (5)로 이동합니다. show에는 h가 있기 때문입니다.
(5)로 넘어가고 나서는 b와 w를 비교합니다.
눈치채셨을 수도 있겠지만, 패턴의 제일 뒤(오른쪽)부터 검사합니다.

좀 더 자세하게 살펴보면, 매칭 실패 시 이동 거리 표를 확인할 수 있습니다.
맨 위 표의 오른쪽끝문자는 입력문자열의 현재 매칭을 확인하는 구역의 맨 오른쪽에 있는 글자를 의미합니다.
첫 번째 예의 경우 h와 t가 다르고, h는 boat에 위치하지 않으므로 etc에 걸려서 4칸 오른쪽으로 이동합니다.
두 번째 예의 경우 o와 t가 다르고, o는 이동 거리 표에서 2에 위치하고 있기 때문에 2칸 오른쪽으로 이동합니다.
그리고 다시 맨 오른쪽부터 비교합니다.

아래는 단순 방법과 Boyer-Moor-Horspool 알고리즘의 수도코드 비교입니다.
가장 눈에 띄는 것은 i의 변동사항입니다.
단순 방법은 i가 1씩 증가하지만, Boyer-Moor-Horspool 알고리즘은 jump리스트에서 요소를 가지고 와서 상황에 따라 한 번에 여러 칸 점프할 수 있습니다.

이 알고리즘의 핵심은 jump 리스트입니다.
첫 문자의 jump값은 글자수-1 이고, 끝 문자의 바로 앞 문자까지 1씩 줄어듭니다.
그리고 마지막 문자의 jump값은 글자수이고, 기타 다른 문자가 들어와도 jump값은 글자수입니다.
같은 문자가 있는 경우 그 문자들을 모두 비교해야하므로 작은 jump값으로 설정합니다.
시간복잡도는 최악의 경우 O(mn)인데, 앞에서 배운 알고리즘들에 비해 한번에 여러 칸 점프할 수 있으므로 훨씬 효율적인 알고리즘입니다.
Boyer-Moore 방법은 이 방법보다 훨씬 정교한 jump 판단 방식을 사용합니다. 아까도 말했지만 Boyer-Moore-Horspool은 Boyer-Moore알고리즘의 방법 중에서 the bad character rule의 방법만을 채용하여 간소화한 방법입니다.

Boyer-Moore-Horspool 알고리즘을 파이썬으로 구현한 코드입니다.
txt파일을 사용하기 때문에 별도로 작성해서 파일을 열 수 있는 환경을 만들어주셔야 정상적으로 돌아갑니다!
# Boyer-Moore-Horspool 알고리즘
def compJump(p): # jump 리스트(딕셔너리)
jump = {}
m = len(p)
for i in range(0,m-1): # 마지막 글자는 어짜피 m이기 때문에 넣지 않았다!!
jump[p[i]]=m-i-1
return jump
def BMH(a, p):
jump = compJump(p) # jump 딕셔너리 생성
m= len(p)
n = len(a)
i = 0
while(i<= n-m): # 끝까지 돌리기
j=m-1
k=i+m-1
while(j>=0 and p[j]==a[k]): # 글자가 같으면 이전 인덱스로 넘어가서 다시 비교
j-=1
k-=1
if j == -1: # 다 같으면 인덱스 출력
print("matching is found at ", i)
if a[i+m-1] in jump : # jump에 있으면 그만큼 jump
i += jump[a[i+m-1]]
else: # 없으면 m만큼 점프
i+=m
p="school"
f = open('textfile2.txt','r')
# f.read는 파일 전체를 읽어 온다.
text = f.read()
BMH(text, p) # txt파일 전체에서 school을 찾아서 시작 인덱스를 출력한다.
f.close()
# line 단위로 check. 파일의 모든 줄을 lines로 읽어 온다.
f = open('textfile2.txt','r')
lines = f.readlines()
f.close()
jj=1
for line in lines: # 첫 줄과 세번째 줄에서는 출력되지 않고, 두 번째 줄에서만 출력된다.
print(jj)
jj+=1
BMH(line,p)

3. 마무리
길었던 알고리즘 분석 포스팅도 드디어 끝입니다.
뒤로 갈수록 포스팅의 길이도 길어져서 언제 끝나나 오매불망 기다렸는데 드디어 끝났네요..!

알고리즘분석 수업의 목표는 좋은(효율적인) 알고리즘을 구축하는 것이었습니다.
이걸 위해 복잡도를 표현하고 분석하는 방법에 대해 배우고 각종 알고리즘들에 대해서 배웠죠.
말로만 알고리즘, 알고리즘 하다가 실제로 알고리즘을 배우고 분석해보니 정말 어려운 것이라는 것을 몸소 느낄 수 있었습니다.
아마 저도 시간이 지나면 다 까먹고 다시 포스팅을 보면서 이걸 도대체 어떻게 했지 푸념하고 있을지도 모르겠네요 ^^;;;
그만큼 여러분들도 여기까지 따라오셨다면 정말 대단한 분들이라고 생각합니다.
분명 알고리즘 실력도 저보다 훨씬 뛰어나실 거라고 생각해요. 저는 아직 많이 부족한 비전공 학생이고, 제 설명은 분명 완전하지는 않다고 생각하구요!
그렇기 때문에 제가 잘못 적은 부분이 있다면 언제든지 피드백 주시면 감사하겠습니다!
그렇다면!! 다른 카테고리에서도 여러분과 함께할 수 있으면 좋겠습니다 :) 다시 한 번 감사드립니다!! 🏃🏃🏃
p.s. 컴퓨터공학과 한치근 교수님 항상 유익한 수업을 해주셔서 감사드립니다!!








최근댓글