
알고리즘분석 카테고리의 마지막은 검색의 계산복잡도에 대한 내용이 되겠습니다.
이번 포스팅에서는 검색 방법들의 계산복잡도를 알아보도록 하겠습니다.
목차
0. 검색의 하한
먼저 검색 문제의 정의부터 알아보도록 합시다.
검색 문제는 n개의 키를 가진 배열 S와 어떤 키 x가 주어졌을 때, x = S[i]가 되는 첨자 i를 찾는 것입니다.
만약 x가 배열 S에 없다면 오류로 처리해야하죠.
이전 포스팅에서 배웠던 정렬을 이용해서 배열을 정렬한 후에 이진(이분) 검색 알고리즘을 사용하면 시간복잡도가 W(n) = floor(lg n) + 1이 되어서 매우 효율적인 알고리즘을 만들 수 있습니다.
(floor는 내림, ceil은 올림입니다!)
그렇다면 이진 검색보다 더 좋은 알고리즘을 만들 수 있을까요?
정답은 아니다입니다. 키의 비교만으로 검색을 수행하는 경우 이진 검색 알고리즘보다 더 좋은 알고리즘은 존재할 수 없습니다.
이진 검색과 순차 검색을 살펴보면서 위 내용을 증명하도록 하겠습니다.
7개의 키를 검색하는 문제를 예로 들겠습니다.
이진 검색의 경우 최악의 경우 3번의 비교까지 진행됩니다. 아래 사진에서 F의 경우 비교 구문이 논리에 맞지 않아 답을 구할 수 없는 경우입니다.
아래 그림에서는 결과가 3가지로 나눠지는데, 값을 비교하여 검색하는 것을 결정트리의 비교노드만을 포함하는 트리(>, <)로 표현하면 이진트리가 됩니다.

순차 검색의 경우 특정 값과 같지 않으면 다음 값으로 넘어갑니다. 그렇기 떄문에 최대 7번까지 비교하게 됩니다.

두 결정트리 모두 x를 찾기 위해서 n개의 키를 검색할 수 있기 때문에 유효하고(valid), 모든 잎에 도달할 수 있으므로 가지친 결정트리(pruned)라고 부를 수 있습니다.
이제 두 검색 방법의 최대 검색횟수의 하한을 알아봅시다.
이분 검색의 경우 최대 3번의 비교, 순차 검색의 경우 최대 7번의 비교가 필요합니다.
※ 최악일 때 하한
최악의 경우 비교하는 횟수는 결정트리의 root에서 leaf까지 가장 긴 경로상의 비교마디 수인데, 이는 (트리의 깊이 + 1)이 됩니다.
위 내용을 기억한 상태로 보조정리 2가지를 통해 하한을 확인해보겠습니다.
보조정리 1은 n이 이진트리의 마디의 개수이고, d가 깊이이면 d >= floor(lg n)입니다.
각 단계별로 나올 수 있는 최대한의 마디 수를 구해서 n과 비교를 하면 됩니다.
이 과정에서 2의 지수형태가 나오는데, 로그를 이용하여 없애줍니다.

보조정리 2는 n개의 다른 키 중에서 어떤 키 x를 찾는 가지친 유효 결정트리(pruned, valid)는 비교하는 마디가 최소한 n개 있다는 것입니다.
이 말은 n개가 있어야 어떠한 경우에도 x라는 특정한 키를 찾을 수 있다는 말이 됩니다.
위 내용들을 정리하면 n개의 다른 키가 있는 배열에서 어떤 키 x를 찾는 알고리즘은 키를 비교하는 횟수를 기준으로 했을 때 최악의 경우 최소한 floor(lg n) + 1 만큼의 비교를 한다는 결론을 얻을 수 있습니다.
알고리즘의 결정트리에서 비교하는 마디만으로 이루어진 이진트리를 보면 최악의 경우 비교횟수는 root에서 leaf로 가는 모든 경로 중 가장 긴 경로의 마디 수가 됩니다. 그리고 그 수는 이진트리의 깊이 + 1이 되죠. (위 그림에서는 총 7개의 요소이고 depth가 2인데, 가장 긴 경로의 경우 3번 비교를 하게 됩니다)
그런데 보조정리 2에서 이 이진트리의 마디수는 n이라고 했기 때문에 그 이진트리의 깊이는 floor(lg n)보다 크거나 같습니다.(어떻게 n개의 마디를 이진트리에 채워도 트리의 깊이가 floor(lg n)보다 낮은 경우는 없습니다)
그래서 최소한 floor(lg n) + 1 만큼 비교를 하게 됩니다.
그런데 이진 검색의 시간복잡도가 W(n) = floor(lg n) + 1이었죠?
따라서 이진 검색 방법이 검색 문제의 최선의 해결 알고리즘이라는 것을 알 수 있었습니다.
※ 평균일 때 하한
평균일 때 하한의 경우 비슷한 방식으로 구할 수 있습니다.
그 결과 검색문제의 평균 하한은 floor(lg n) - 1이 됩니다.
아래는 이진 검색의 수도코드, 그리고 이진 검색을 파이썬으로 구현한 코드입니다.
별 다른 어려운 내용이 없기 때문에 주석만 읽으셔도 쉽게 이해하실 수 있을 것이라고 생각합니다.

# 이진 탐색
def binsearch(n, s, x):
low = 0
high = n-1
location = -1 # 만약 찾지 못하면 -1 출력
while low <= high and location == -1: # low가 high보다 작거나 같고, location이 -1이라면(아직 찾지 못했다면)
mid = (low + high) // 2
if x == s[mid]: # 찾았으면
location = mid # location에 위치 삽입
break
elif x < s[mid]: # x가 s[mid]보다 작으면 (비교값 s[mid]가 원하는 값 x보다 크면)
high = mid - 1 # 비교값 기준 왼쪽으로 검색범위 축소
else: # x가 s[mid]보다 크면 (비교값 s[mid]가 원하는 값 x보다 작으면)
low = mid + 1 # 비교값 기준 오른쪽으로 검색범위 축소
return location # location 반환
s = [7,9,1,3,12]
n = len(s)
x = 12 # 찾고 싶은게 12
print(binsearch(n,s,x)) # 인덱스번호 4에 x가 위치해있다
1. 보간검색
그렇다면 검색의 하한을 개선할 수 있을까요?
키의 비교 이외에 다른 추가적인 정보를 이용하여 검색할 수 있다면 가능합니다.
만약 10개의 정수를 검색하는데 첫 번째 정수가 0~9중 하나이고, 두 번째 정수는 10~19중 하나이고... 열 번째 정수가 90~99중 하나라면, 검색키 x가 0보다 작거나 99보다 크면 바로 검색이 실패임을 알 수 있고, 그렇지 않으면 x와 s[1+x*div10]을 비교하면 됩니다.

또 다른 보간 검색 방법으로 선형 보간법(linear interpolation)이 있습니다.
선형 보간법은 두 개의 관찰점을 바탕으로 특정 점의 값을 추정하는 방법입니다.
두 개의 관찰점이 각각 a=(10,30), b=(100,60)이라면, 두 점을 연결한 선을 바탕으로 c=(70,?)에서 ?를 추정할 수 있습니다.

보간검색(interpolation search)는 일반적으로 데이터가 가장 큰 값과 가장 작은 값이 균등하게 분포되어 있다고 가정하여 키가 있을만한 곳을 바로 가서 검사하는 방법입니다.
보간검색의 대표적인 예인 선형 보간법에서 했던 것처럼 키 값 자체를 이용하는 것이죠.

여기서 구한 mid식을 그대로 선형 보간법에 사용해보도록 하겠ㅆ브니다.
만약 S[1] = 4이고 S[10] = 97일 때 검색하고 싶은 키가 25라면, mid는 3이 됩니다.

이런 선형 보간법은 아이템이 균등하게 분포되어 있고, 검색 키가 각 슬롯에 있을 확률이 같다고 가정하면 선형보간검색의 평균적인 시간복잡도는 lg(lg n)이 됩니다. n이 10억이라면 lg(lg n)은 약 5가 되는 것이죠.
하지만 최악의 경우를 생각해보면, 만약 10개의 아이템이 1,2,3,4,5,6,7,8,9,100이고 여기서 10을 찾으려고 한다면 mid값이 항상 low값이 됩니다. 즉 모든 아이템과 비교를 해야한다는 이야기죠.
이렇게 최악의 경우라면 시간복잡도는 순차검색의 시간복잡도인 O(n)과 같아집니다.

아래 수도코드와 파이썬 코드는 보간 검색을 구현한 코드입니다. (배열 내에 값이 없으면 -1이 출력됩니다.)

# 보간 검색
import math
def interpsrch(n, s, x):
low = 0
high = n-1
i = -1 # 발견한 정답
if s[low] <= x and x <= s[high]: # 찾으려는 값이 최솟값과 최댓갑 범위 안에 들어가면
while low <= high and i == -1: # 아직 값을 발견 못했다면 계속 반복
denominator = s[high] - s[low]
if denominator == 0:
mid = low
else:
mid = low + math.floor(((x-s[low])*(high-low))/denominator) # 보간법을 위한 식
if x == s[mid]:
i = mid
break
elif x < s[mid]:
high = mid - 1
else:
low = mid + 1
return i
n = 5
s = [1,3,5,7,9]
x = 5
print(interpsrch(n,s,x))
지금까지 배운 보간검색을 조금 더 보완한 보강된 보간검색(robust interpolation search)도 있습니다.
- gap 변수를 만듭니다.
- gap의 초기값을 floor(root(high - low + 1))로 설정합니다.
- mid값을 위와 같은 선형보간법으로 구합니다.
- mid = MIN(high - gap, MAX(mid, low + gap))
보강된 보간검색을 1,2,3,4,5,6,7,8,9,100의 아이템에서 x=10을 찾는 케이스에 대입해보면 아래와 같습니다.
일반 보간검색은 mid가 1이 나왔는데, 보강된 보간검색에서는 mid가 4가 나옵니다.

아이템이 균등하게 분포되어 있고, 검색 키가 각 슬롯에 있을 확률이 같다고 가정하면 보강된 보간검색의 평균 시간복잡도는 O(lg(lg n))이고, 최악의 경우는 O((lg n)^2)가 됩니다.
최악의 경우가 좀 더 나아진 모습을 볼 수 있죠.
2. 이진검색트리
이번에는 트리 구조를 사용한 동적검색에 대해 알아보겠습니다.
정적검색(static searching)은 데이터가 한꺼번에 저장되어 추후에 추가나 삭제가 이루어지지 않는 경우에 이루어지는 검색입니다. 예를 들면 OS명령에 의한 검색 등이 있습니다.
동적검색(dynamic searching)은 데이터가 수시로 추가나 삭제되는 유동적인 경우 이루어지는 검색입니다. 예를 들면 비행기 예약 시스템이 있습니다.
배열 자료구조를 사용하면 정적검색의 경우 문제없이 이진검색이나 보간검색 알고리즘을 적용할 수 있지만, 동적 검색의 경우에는 이 알고리즘을 적용할 수 없습니다. (배열의 경우 메모리를 얼마나 사용할 것인지를 정해놓기 때문에 추가로 데이터를 넣거나 뺄 때 제한일 있을 수 있기 때문입니다.)
따라서 이런 경우에는 트리 구조를 사용해야 합니다.
이제 이진검색트리에 대해 알아보겠습니다.
이진검색트리(binary search tree)는 다음 조건을 만족하는 트리입니다.
- 각 마디마다 하나의 키가 할당되어 있습니다.
- 어떤 마디 n의 왼쪽부분트리(left subtree)에 속한 모든 마디의 키는 그 마디 n의 키보다 작거나 같습니다.
- 어떤 마디 n의 오른쪽부분트리(right subtree)에 속한 모든 마디 n의 키보다 크거나 같습니다.


이진검색트리를 사용하고 inorder traversal(왼쪽자식, 본인, 오른쪽 자식) 순으로 순회한다면 정렬된 순서대로 아이템을 추출할 수 있습니다.
하지만 동적으로 트리에 아이템을 추가하고 삭제할 때 트리가 항상 균형을 유지한다는 보장은 없습니다.
최악의 경우에는 연결된 리스트를 사용하는 것과 같은 효과가 날 수도 있죠. (예를 들면 skewed tree)
그렇기 때문에 랜덤하게 아이템이 트리에 추가되도록 하면 대체로 트리가 균형을 유지할 수 있게 됩니다. (평균적으로 효율적인 검색시간을 기대할 수 있습니다.)
실제로 아이템이 추가되고 삭제되는 경우를 살펴보겠습니다.
먼저 추가되는 경우를 살펴보겠습니다.
아래 사진에서 3.5가 추가되는 경우 4, 2, 3과 비교 후에 자신의 위치를 찾아 들어가게 됩니다.

삭제되는 경우는 두 가지 케이스로 나눌 수 있습니다.
먼저 두 개의 자식노드가 있는 노드가 삭제되는 경우에는 왼쪽 자식의 맨 오른쪽 요소가 삭제되는 요소 위치로 가거나, 오른쪽 자식의 맨 왼쪽 요소가 삭제되는 요소 위치로 갈 수 있습니다.

한 개의 자식노드가 있는 노드가 삭제되는 경우는 자식노드가 바로 삭제되는 부모노드의 위치로 오게 됩니다.

이진검색트리의 검색을 분석해보겠습니다.
검색하는 아이템 x가 n개의 아이템 중 하나가 될 확률이 모두 동일하다고 가정하면 이진검색트리의 평균검색시간(A(n))은 대략 1.38 lg n 이 됩니다. n개의 노드를 가진 트리의 트리 높이가 lg n이기 때문에, 1.38 lg n은 굉장히 효율적이라고 볼 수 있습니다. (생성 가능한 모든 이진검색트리에 대한 평균검색시간입니다!)
이것을 증명해보도록 하겠습니다.
k번째로 작은 아이템이 root에 위치하고 있는 n개의 아이템을 가진 이진검색트리를 가정합니다.
그렇다면 왼쪽부분트리에는 k-1개의 마디가 있고, 오른쪽 부분트리에는 n-k개의 마디가 존재하게 됩니다.
A(k-1)은 왼쪽 부분트리를 검색하는 평균검색시간이고, A(n-k)는 오른쪽 부분트리를 검색하는 평균검색시간입니다.
모든 아이템들의 확률이 동일하기 때문에 x가 왼쪽 부분트리에 있을 확률은 (k-1)/n이 되고, 오른쪽 부분트리에 있을 확률은 (n-k)/n이 됩니다.
A(n|k)를 크기 n의 입력에 대하여 k번째로 작은 아이템이 뿌리마디에 위치하고 있는 이진검색트리의 평균검색시간이라고 하겠습니다. (A(n|k) = k가 주어진 상태에서 n개의 노드가 있는 트리의 평균검색시간)

위 내용을 바탕으로 계산해보도록 하겠습니다.
A(n|k)는 A(k-1)에다가 왼쪽 부분트리로 넘어갈 확률인 (k-1)/n을 곱해준 값과 A(n-k)에다가 오른쪽 부분트리로 넘어갈 확률인 (n-k)/n을 곱해준 값을 더해주고, 뿌리마디에서의 비교인 1을 더해줍니다.
n개의 마디에서 k를 찾는 평균식을 일반화했으니, 이 일반화된 식을 이용하여 A(n)을 구할 수 있습니다.
A(n)은 k가 1부터 n인 경우를 다 더하고 1/n으로 나눠주면 되겠죠?
이제 A(1) = 1을 이용하면 A(n)을 구할 수 있습니다. 퀵정렬(Quick sort)의 시간복잡도 계산과 거의 유사하기 떄문에 자세한 식은 아래로 대체합니다.
하지만 결과적으로 최악의 경우 시간복잡도는 O(n)이기 때문에 항상 효율적이라고는 볼 수 없습니다.

이전에 배웠던 동적계획법의 최적이진검색트리 구축 방법에서는
- 각 트리 내에 각 노드를 찾을 확률을 A[i][i] = p_i로 설정합니다.
- 하나의 고정 모양의 이진검색트리에서 검색하는데 필요한 평균 시간을 계산합니다.
특히 동적계획법에서는 두 번째, 하나의 고정 모양의 이진검색트리 검색에 필요한 평균 시간을 계산한 내용이기 때문에, 가능한 모든 이진검색트리 형태에 대한 평균 시간을 계산한 A(n)과는 차이가 나게 됩니다.
(보통 동적계획법에서는 각 키를 찾을 확률이 다릅니다!)
본 내용은 동적계획법 포스팅의 3번을 참고하시면 조금 더 자세하게 아실 수 있습니다.
[알고리즘분석] 2. 동적계획법
이번 포스팅에서는 동적계획법에 대해서 알아보도록 하겠습니다. 동적계획법은 앞서 배운 분할정복 방법과 반대인 상향식 해결방법(bottom up)입니다. 분할정복식처럼 문제를 나눈 후에 나누어진
ssocoit.tistory.com


2.0. 검색시간 향상을 위한 트리구조
이제 이진검색트리 내에서 검색시간 향상을 위한 트리구조를 어떻게 구성해야 할 지에 대해 알아봅시다.
가장 필요한 것은 가능한 새롭게 들어오는 아이템이 root와 멀어지지 않도록 하는 것이겠죠?
밸런싱 작업을 통해 skewed tree가 생기지 않도록 만든다면 그것이 바로 균형이진검색트리입니다.

균형트리에는 다양한 트리들이 존재합니다.
이번 포스팅에서 알아볼 트리들은 모두 추가, 삭제, 검색에 O(lg n)시간이 걸리게 됩니다.
- AVL트리
- B-트리
- red-black tree
2.1. AVL트리
AVL트리는 좌우 subtree의 높이의 차가 최대 1인 이진탐색트리입니다.
왼쪽 이진탐색트리의 경우는 9에서 왼쪽 자식트리의 높이가 0인데, 오른쪽 자식트리의 높이는 2입니다.
높이의 차가 2이므로 이진탐색트리의 조건에서 벗어납니다.
오른쪽 이진탐색트리의 경우 어떤 부분에서도 좌우 subtree의 높이의 차가 1을 넘지 않습니다.
따라서 AVL트리입니다.

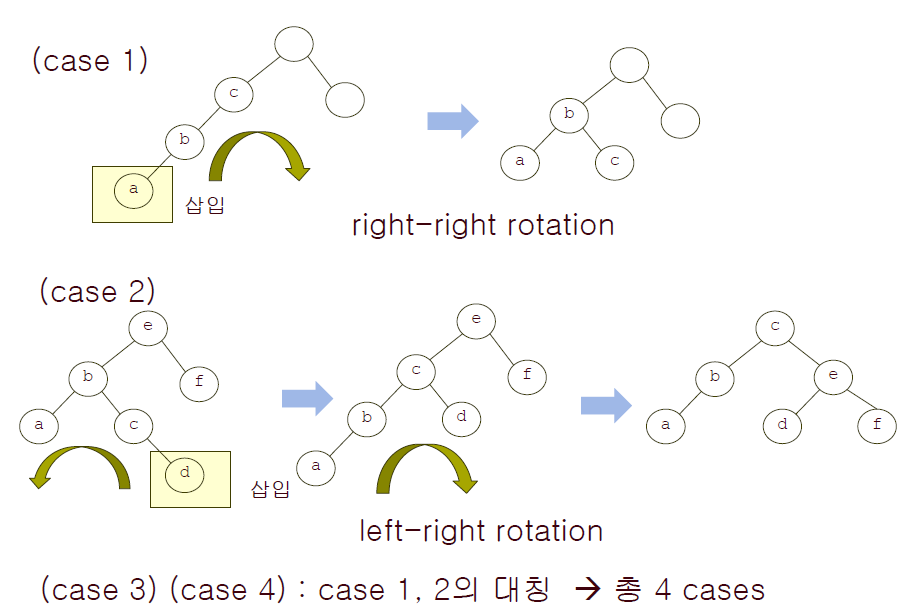
AVL트리에서 데이터를 추가할 때 균형을 유지하기 위해서는 특별한 조작이 필요합니다.
case1의 경우 c의 왼쪽과 오른쪽의 높이가 달라지기 때문에, right-right rotation(RR 회전)을 통해 c를 b의 오른쪽 아래로 내립니다.
case2의 경우 e의 왼쪽과 오른쪽의 높이가 달라지기 때문에, left-right rotation(LR 회전)을 통해 균형을 맞춰줍니다.
case3, case4는 case1, case2의 대칭입니다.
총 4가지의 상황을 서브트리 회전을 통해 다룰 수만 있다면 AVL트리에서 균형을 유지할 수 있습니다.
- RR 회전 : 새로 삽입된 노드가 조상 노드의 왼쪽 서브트리의 왼쪽 서브트리에 삽입되었을 때 경로상의 노드들을 오른쪽으로 회전합니다.
- LL 회전 : 새로 삽입된 노드가 조상 노드의 오른쪽 서브트리의 오른쪽 서브트리에 삽입되었을 때 경로상의 노드들을 왼쪽으로 회전합니다.
- RL 회전 : 새로 삽입된 노드가 조상 노드의 오른쪽 서브트리의 왼쪽 서브트리에 삽입되었을 때 경로상의 노드들을 오른쪽으로 회전한 후 왼쪽으로 회전합니다.
- LR 회전 : 새로 삽입된 노드가 조상 노드의 왼쪽 서브트리의 오른쪽 서브트리에 삽입되었을 때 경로상의 노드들을 왼쪽으로 회전한 후 오른쪽으로 회전합니다.
2.2 B-tree
B-tree는 이진트리와는 다르게 하나의 노드에 많은 수의 정보를 가진 트리입니다.
그 중에서 가장 간단한 2-3트리의 특징은 아래와 같습니다.
- 2-3트리의 각 마디에는 키가 하나 혹은 두 개가 존재합니다.
- 각 내부마디의 자식 수는 키의 수+1입니다.
- 어떤 주어진 마디의 왼쪽/오른쪽 부분트리의 모든 키들을 그 마디에 저장되어 있는 마디보다 작거나(크거나) 같습니다.
- 모든 leaf의 수준이 같습니다.
- 데이터는 트리 내의 모든 노드에 저장됩니다.

아래 2-3트리의 예시가 있습니다.
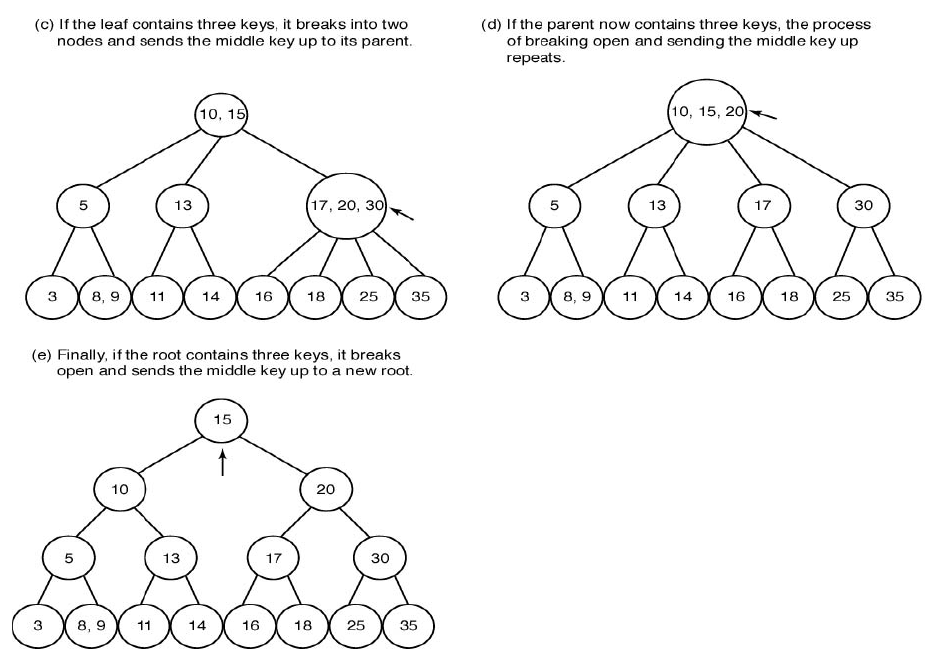
35를 추가한다고 할 때, 키값이 3개가 들어가는 노드가 생기게 됩니다.
이런 경우 가운데 요소가 위로 올라갑니다.
위로 올라가면 17, 20, 30 3개의 요소가 다시 만나게 되는데, 다시 한 번 가운데 20이 위로 올라갑니다.
그리고 나눠지면서 자식 노드들도 2개씩 나눠가지게 됩니다.
20이 올라가서 10, 15, 20이 다시 한 노드에 모이게 되는데, 이제 가운데인 15가 새롭게 위로 올라갑니다.
그렇게 되면 최종적으로 2-3트리가 정리됩니다.

2.3. Red-black tree
마지막으로 Red-black tree입니다!
한국말로 적흑나무..인데 너무 어색하니 레드블랙트리라고 하겠습니다! (세종대왕님 죄송합니다..)
오름차순으로 정렬된 레드블랙트리의 특징은 다음과 같습니다!
- 모든 노드는 빨강 아니면 검정입니다. (그러니까 red-black이지..)
- root 노드의 색깔은 검정입니다.
- 모든 leaf는 검정입니다.
- 삽입되는 모든 노드는 빨강입니다.
- 노드가 빨강이면 그 노드의 자식은 모두 검정입니다. (No double red라고도 불리는 조건입니다!)
- 각 노드로부터 그 노드의 자식인 leaf로 가는 경로는 모두 같은 수의 검정 노드를 포함합니다.

조금 의아한 점이 있을 수 있는데, 삽입되는 모든 노드가 빨강이라는 점입니다.
빨간 노드가 연속해서 나올 수 없는데, 빨간색만 넣는다면 당연히 연속해서 나올 수밖에 없겠죠?
이 경우 부모의 형제(uncle node)의 색깔이 빨간색이면 Recoloring, 검은색이면 Restructuring을 사용합니다.
Recoloring은 삽입된 노드의 부모와 삼촌 노드를 검정으로, 부모의 부모 노드를 빨강으로 Coloring합니다.
부모의 부모노드가 Root라면 그대로 검정으로 두고, 만약 Double Red가 다시 발생하는 경우 다시 규칙에 맞게 Recoloring 혹은 Restructuring을 사용합니다.
아래 예에서는 4를 빨강으로 바꾸고 3,5를 검정으로 바꿉니다.
Restructuring의 경우 삽입된 노드, 부모 노드, 부모의 부모노드를 오름차순으로 정렬합니다.
중앙 값을 부모 노드로 만들고 나머지 노드를 자식으로 변환합니다.
부모 노드가 된 노드를 검정으로, 나머지 노드를 빨강으로 변환합니다.
아래 예에서는 5, 7, 6을 순서대로 정렬하고, 가운데값인 6을 부모 노드로 만들고 나머지 5,7을 자식 노드로 만듭니다.
그리고 원래 5의 자식이었던 남은 3을 추가해줍니다.

두 케이스 모두 자신의 위치를 찾기 위해 O(lg n)시간이 걸리게 됩니다.
Recoloring은 Root까지 올라갈 가능성이 있으므로 O(lg n)시간이 추가로 걸리게 되고, Restructuring의 경우는 다른 서브트리에 영향을 끼치지 않기 때문에 O(1)이 걸립니다.
결과적으로 두 케이스의 시간복잡도는 O(lg n)이 되겠죠!!
(2 lg n 이나 lg n + 1이나 결국 Big-O notation에서는 lg n입니다!)
내용이 너무 길어지지 않기 위해서 여기서 끊도록 하겠습니다!!
다음 내용은 해싱과 문자열 매칭 등에 대한 내용인데, 이 부분도 너무 길어진다면 [계산복잡도 : 검색] 에 대한 내용을 3개의 포스팅으로 나눠서 포스팅하게 될 수도 있을 것 같습니다.
마지막으로 갈수록 내용이 기네요... ㅠ
거의 다 왔습니다! 마지막까지 파이팅해서 완강합시다 :) 그렇다면 다음 포스팅에서 뵙겠습니다!!








최근댓글