
깔끔하게 정렬되어있는 저 펜들도 처음에는 막 흐뜨러져 있었을 수 있습니다.
저 친구들을 올바른 자리에 똑바로 정렬시키는 것도 하나의 알고리즘이라고 할 수 있겠죠?
이전 포스팅에서 O(n^2)의 시간복잡도를 가진 친구들에 대해서 알아봤다면,
이번 포스팅에서는 보다 나은 효율(O(n lg n))을 가진 알고리즘들에 대해서 공부할 예정입니다.
바로 내용으로 넘어가시죠!
목차
0. 합병정렬
합병정렬은 분할정복의 대표적인 예시입니다.
분할정복은 문제를 작은 2개의 문제로 분리하고 각각을 해결한 뒤 결과를 모아서 원래의 문제를 해결하는 방법을 사용합니다.
합병정렬은 하나의 리스트를 두 개의 균등한 크기로 분할하고 분할된 부분 리스트를 정렬한 다음 두 개의 정렬된 부분 리스트를 합하여 전체가 정렬된 리스트가 되게 만드는 방법입니다.
실질적으로 정렬이 되는 부분은 합쳐지는 부분이 되고, 합쳐질 때는 새로운 리스트를 만들어서 그 곳에 저장합니다.
이 합병정렬의 특징으로는 정렬을 할 때 새로운 메모리 공간이 필요합니다.


합병정렬을 파이썬으로 구현한 코드입니다.
필요한 부분에 주석을 달아놓았으니, 이해하는데 도움이 되셨으면 좋겠습니다!
# 합병정렬
def mergeSort(n, s):
h=int(n/2)
m=n-h
u=h*[0]
v=m*[0]
if(n>1): # 반으로 쪼개기
leftHalf=s[:h]
rightHalf=s[h:]
mergeSort(h,leftHalf)
# h=len(leftHalf)이다!!
mergeSort(m,rightHalf)
merge(h,m,leftHalf,rightHalf,s)
def merge(h,m,u,v,s):
i=j=k=0
while(i<=h-1 and j<=m-1): # 비교해서 더 작은쪽을 s에 넣어준다
if(u[i]<v[j]):
s[k]=u[i]
i+=1
else:
s[k]=v[j]
j+=1
k+=1
if(i>h-1): # 나머지 s에 넣어주기
for ii in range (j,m):
s[k+ii-j]=v[ii]
else:
for ii in range (i,h):
s[k+ii-i]=u[ii]
s=[3,5,2,9,10,14,4,8]
mergeSort(8,s)
print(s)

합병정렬의 경우 시간복잡도가 O(n lg n)입니다.
분할 과정이 매번 반씩 감소하기 때문에 최대 lg n만큼 반복해야 크기가 1인 배열로 모두 분할할 수 있습니다.
8개의 요소를 가지고 있다면 순환 호출은 최대 3번까지 하게 되는 것이죠.
그리고 각 합병 단계에서 분할된 요소들을 비교하는데 최대 n번이 필요합니다.
즉 비교연산의 경우 n lg n번이 발생하게 되죠.
할당 횟수는 임시배열에 복사했다가 다시 가져오기 때문에 요소당 총 2번 발생합니다. 전체 요소에서 2n번 발생하는 것이죠.
그리고 순환 호출이 lg n번 발생하기 때문에 할당은 (2n lg n)번 일어납니다.
만약 요소가 배열로 되어있다면 새로운 임시배열을 만들기 때문에 제자리 정렬이 불가능합니다.(O(n)만큼의 메모리가 필요합니다.)
하지만 Linked-list 형태라면 인덱스만 변경하는 형식이기 때문에 제자리 정렬이 가능하죠.
마지막으로 키값이 같다면 합병할 때 위치가 변하지 않기 때문에 stable한 알고리즘입니다.
이전 포스팅에서 역에 대한 이야기를 했습니다.
기존 단순한 정렬들의 경우 한 번 비교할 때 하나의 역을 제거했었는데, 합병정렬은 비교마다 하나 이상의 역을 제거하므로 보다 효율적입니다.

1. 퀵정렬
퀵정렬은 하나의 리스트를 기준이 되는 요소인 피벗을 기준으로 작은 요소와 큰 요소로 분할하고 분할된 부분 리스트를 정렬한 다음 두 개의 정렬된 부분 리스트를 합하여 전체가 정렬된 리스트가 되게 하는 방법입니다.
순환 호출이 한 번 일어날 때마다 적어도 피벗 원소는 최종적으로 위치가 정해지기 때문에 정렬이 되는 구조입니다.
만약 맨 앞 요소를 피벗으로 한다면, 그 다음 요소를 low, 맨 마지막 요소를 high라고 지정합니다.
low에 있는 요소가 피벗보다 작다면 low를 한 칸 뒤로 보내고, 피벗보다 크다면 멈춥니다.
high에 있는 요소가 피벗보다 크다면 high를 한 칸 앞으로 보내고, 피벗보다 작다면 멈춥니다.
둘 다 멈췄다면, low와 high 요소를 바꿔줍니다.
그 다음엔 low는 한 칸 뒤로, high는 한 칸 앞으로 옮긴 후 진행합니다.
이렇게 진행하다가 low와 high가 엇갈려서 지나가는 순간 멈춥니다.
그리고 high와 pivot의 요소를 바꿔주면 첫 단계가 끝이 납니다.
그 다음부터는 피벗을 기준으로 나눠진 리스트들을 이용해서 다시 퀵정렬을 시작합니다.
이렇게 해서 리스트의 크기가 0 혹은 1이 될 때까지 진행합니다.

퀵 정렬에 대한 수도코드입니다.
partition 함수를 이용하여 피벗포인트를 정위치에 놓고 피벗포인트를 기준으로 양 옆 요소들에 대해 다시 퀵 정렬을 실행합니다.

수도코드를 바탕으로 짠 파이썬 코드입니다.
여기서는 high를 이용하지 않고 low만 이용하는 방식으로 코드를 작성했습니다.
# 퀵정렬
def quickSort(s,low, high):
pivotPoint=-1
if(high>low):
pivotPoint= partition(s,low,high)
quickSort(s,low, pivotPoint-1)
quickSort(s,pivotPoint+1,high)
def partition(s,low,high):
pivotItem=s[low] # 가장 낮은 인덱스를 피벗으로 선택
j=low # 피벗의 인덱스 저장
for i in range(low+1,high+1):
if(s[i]<pivotItem):
j+=1 # 피벗이 들어가야 할 위치의 인덱스 조정
s[i], s[j] = s[j], s[i]; # 위치바꾸기 (여기서는 미리 바꿔버림)
pivotPoint=j # 다 끝나고 j의 위치가 피벗이 원래 들어가야할 지점 (low+1부터 J까지는 피벗보다 작음)
s[low], s[pivotPoint] = s[pivotPoint], s[low] # 피벗이 들어가야 할 지점과 피벗을 바꿔줌
return pivotPoint
s=[3,5,2,9,10,14,4,8]
quickSort(s,0,7)
print(s)
퀵정렬의 경우 매번 절반으로 나눌 수 있다면 lg n번 쪼개고, n번 비교해서 정렬이 가능합니다.
즉 최적일 때 시간복잡도는 O(n lg n)이 되겠죠?
반면 매번 리스트가 불균형하게 나눠지는 경우에는 n번 쪼개고 n번 비교해서 정렬이 가능합니다.
최악일 때 시간복잡도는 O(n^2)이 됩니다.
엄밀하게 따졌을 때 평균 비교 횟수는 (1.38n lg n)입니다.
평균 지정 횟수는 A(n) = (0.69n lg n) 입니다.
그리고 함수가 쪼개질 때마다 pivot을 저장할 공간이 필요하기 때문에 메모리를 (lg n)만큼 사용합니다.
이 말은 제자리 정렬이 아니라는 말이겠죠?
또한 바로 옆에 있는 index끼리가 아닌 멀리 떨어진 요소끼리도 값을 교환하기 때문에 unstable한 알고리즘입니다.
2. 힙정렬
2.0. 힙(heap)
힙정렬을 제대로 파악하기 위해서는 먼저 힙에 대해서 알아야 합니다.
힙은 완전이진트리의 특성을 가지고 있으며, 우선순위 큐에 주로 사용됩니다.
완전이진트리는 꽉찬 트리(Full tree)이거나, 만약 빈 부분이 있다면 맨 아래 레벨의 오른쪽에만 빈 부분이 있는 트리를 말합니다.
그리고 힙은 이런 이진트리의 특성을 만족하면서 부모의 값이 자식의 값보다 크거나(maxheap) 작은(minheap) 특징을 가지고 있습니다.
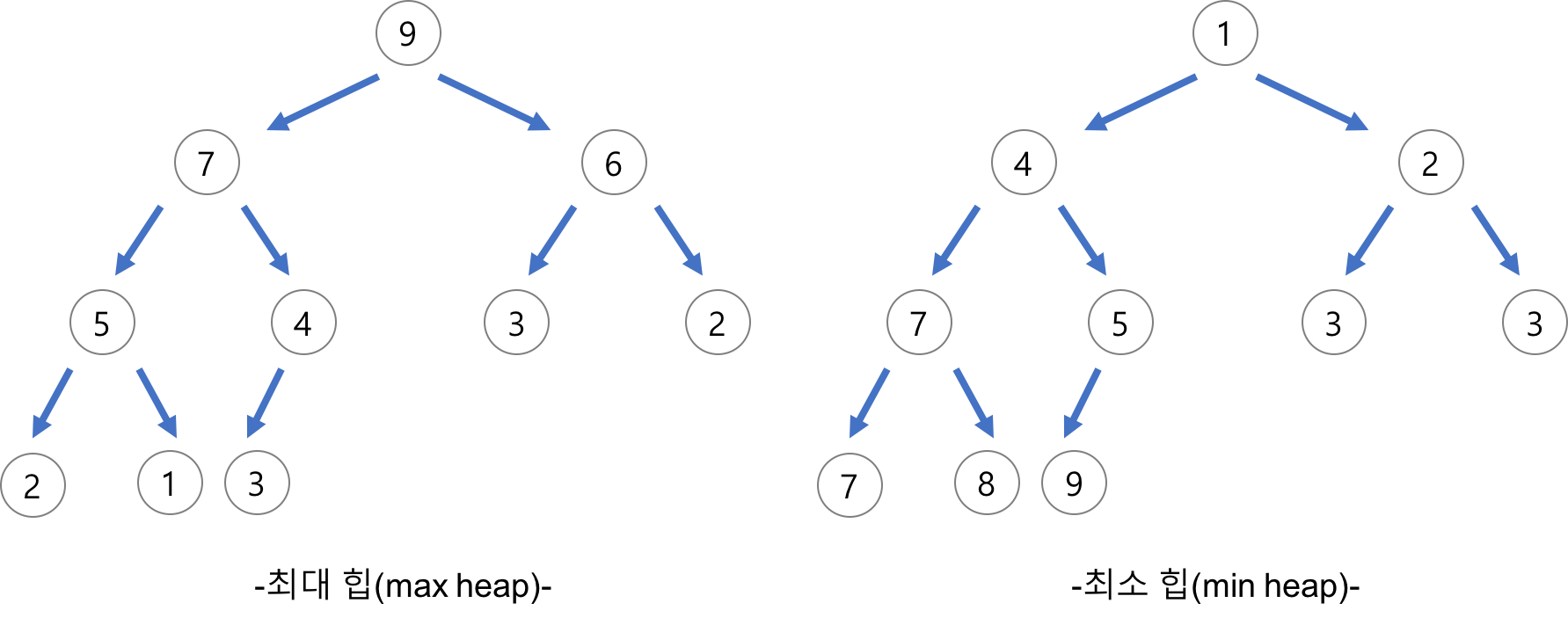

힙 구조의 특성으로는 최대값/최소값을 확인할 때 O(1)의 시간이 걸리고, 최대값을 제거하고 heap을 다시 구조에 맞게 바꿀때는 O(lg n), 데이터의 추가, 삭제, 변경에는 O(lg n)시간이 걸립니다.
그리고 힙 정렬에서 힙을 구현할 때 배열을 사용하도록 하겠습니다.
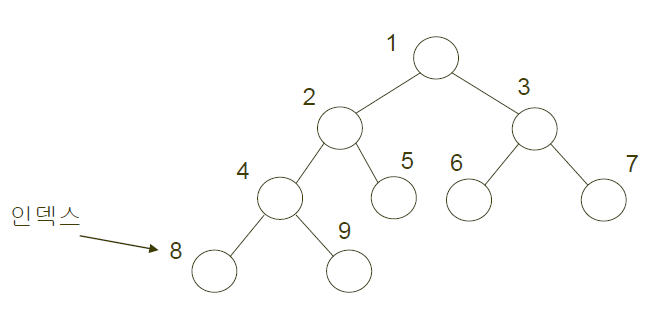
힙 구조를 가진 배열은 이진트리를 배열로 구현했을 때와 같은 방식으로 구현할 수 있습니다.
index i 노드의 왼쪽 자식의 index는 2 * i, 오른쪽 자식의 index는 2 * i + 1, 자신의 부모 노드 index는 n/2를 내림한 값이 됩니다. (이것에 대한 자세한 설명은 생략합니다.)
heap의 경우 어떤 데이터가 나가면 맨 마지막 요소가 맨 위로 갔다가 아래로 내려오면서 재정렬되는 케이스(siftdown)와 어떤 데이터를 추가하면 맨 마지막에 추가한 후 위로 올라가면서 재정렬되는 케이스(siftup) 두 가지가 존재합니다.
sift는 체로 거른다는 뜻을 가진 영어단어입니다.
먼저 siftdown을 살펴보도록 하겠습니다.
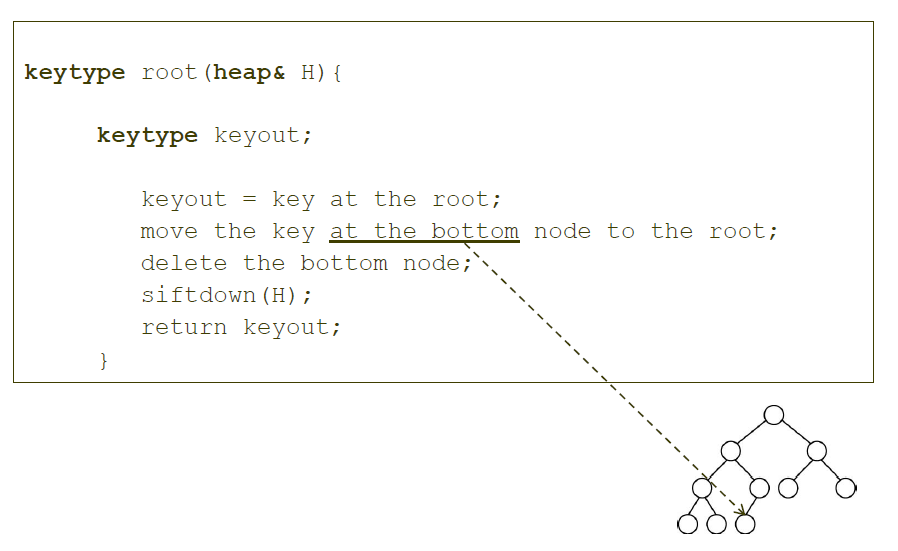
siftdown의 경우 보통 heap에서 루트에 위치한 요소를 빼내고 나서 힙을 정리할 때 사용합니다.
루트에 있는 값을 빼고 맨 마지막에 있는 값을 루트에 넣습니다.
그렇게 되면 루트에 들어간 값에 의해서 힙이 정상적인 상태가 아니게 되었을 수 있습니다.
이 때 자신의 자식들 중에서 더 큰 값과 자신의 위치를 바꿉니다. 그리고 한 칸 내려가서 이 작업을 반복합니다.
이 작업은 더 이상 힙의 조건에 위배되지 않을 때 멈추게 됩니다. (최대한 내려가는데 lg n만큼의 시간이 걸립니다.)
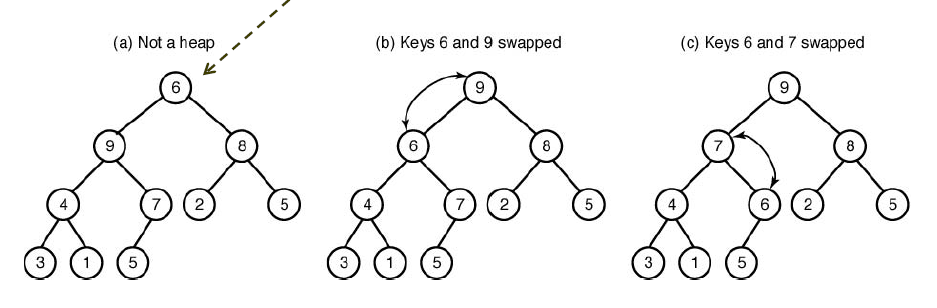
위에서 풀어서 쓴 siftdown에 대한 수도코드입니다.

추가로 siftdown을 사용하는 경우는 heap에서 루트에 위치한 요소를 뺐을 때기 때문에, 루트에 위치한 요소를 빼내는 함수인 root의 수도코드도 첨부합니다.
siftup의 경우는 반대로 힙에 요소를 넣었을 때 주로 사용합니다.
힙의 맨 마지막에 요소를 넣고, 자신의 부모값과 비교해서 자신이 더 크다면 부모값과 위치를 바꿉니다.
이 작업을 맨 꼭대기에 올라갈 때 까지 하거나(최대 O(lg n)) 부모값이 자신보다 클 때 멈춥니다.

2.1. 힙정렬 구현하기
위에서 힙정렬을 만들기 위한 기본 개념인 배열, siftdown, siftup에 대해서 공부했습니다.
그렇다면 이제 실제로 힙정렬이 구성되는데 필요한 것이 무엇인지 알아보고 직접 파이썬으로 구현해보도록 하겠습니다.
힙정렬의 기본 아이디어는 n개의 키를 이용하여 힙을 구성하고, 루트에 있는 제일 큰 값을 제거한 후 힙을 재구성합니다. 제일 큰 값은 임의의 저장소에 저장되어 큰 순서대로 정렬됩니다. (maxheap 기준)
루트에 있는 제일 큰 값을 제거하는 것을 n-1번 반복합니다. 그렇게 되면 마지막까지 정렬이 되고 그 데이터를 가져오면 그대로 정렬된 결과값이 도출되는 것입니다.
힙정렬에 대한 수도코드입니다. removekeys는 값을 하나 빼내는 함수이고, makeheap은 내려가면서 heap을 재정렬합니다(siftdown 사용), heapsort는 배열을 힙으로 만들어주고 요소들을 끝까지 빼내서 순서대로 배열에 저장해서 그 배열을 반환할 수 있도록 만들 수 있습니다.
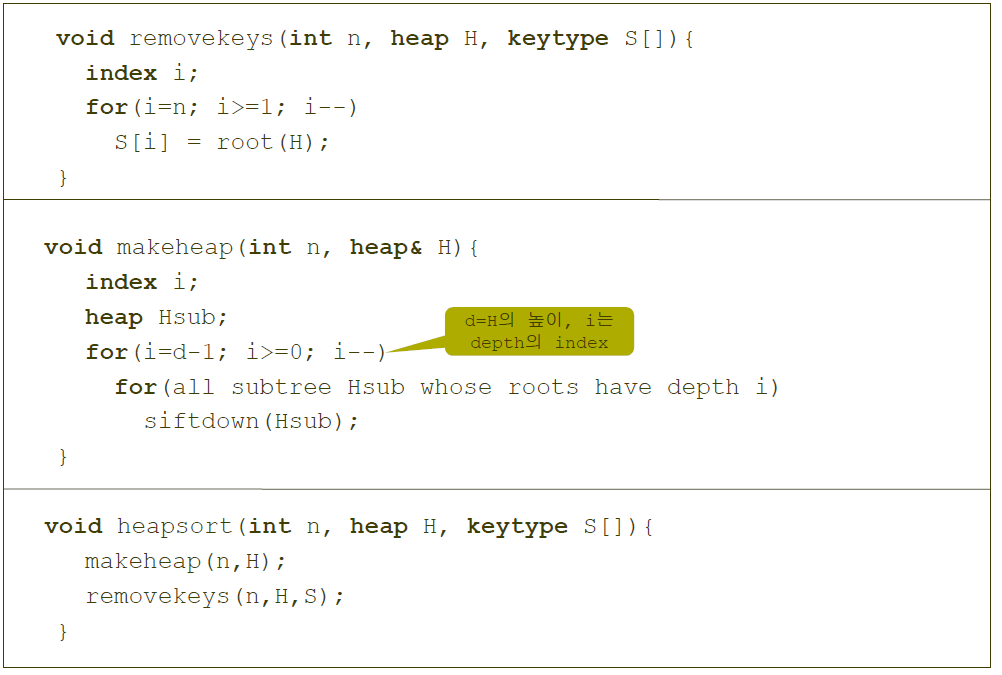
아래 코드는 지금까지 요소들을 모두 정리해서 작성할 수 있는 코드의 일부입니다.

위 코드에서 makeheap 함수는 두 가지로 구분해서 만들 수 있습니다.
- 첫 번째 방법은 데이터가 입력되는 순서대로 heap을 매번 구성하는 방식
- 두 번째 방법은 모든 데이터를 트리에 넣은 상태에서 heap을 구성하는 방식
첫 번째 방법은 배열의 맨 마지막에 요소를 넣고 siftup을 수행해서 heap을 매번 구성하는 방법입니다.
데이터가 10개가 있다면 1개씩 순서대로 넣으면서 heap을 구성하는 것이죠.


이 방법을 사용했을 때의 최악의 경우 시간복잡도를 분석해보겠습니다.
입력의 총 크기는 n이고, 2^k개만큼의 키가 있다고 가정합니다.
d를 트리의 깊이라고 하면 d = lg n이 됩니다.
이 때 d의 깊이를 가진 마디는 정확히 1개이고 그 마디는 d개의 부모노드를 가집니다.
만약 d의 깊이를 가진 마디가 생성되었을 때 siftup을 통해 그 마디가 root까지 올라가는 경우 d번만큼의 비교가 추가적으로 일어나게 되는 것이죠.

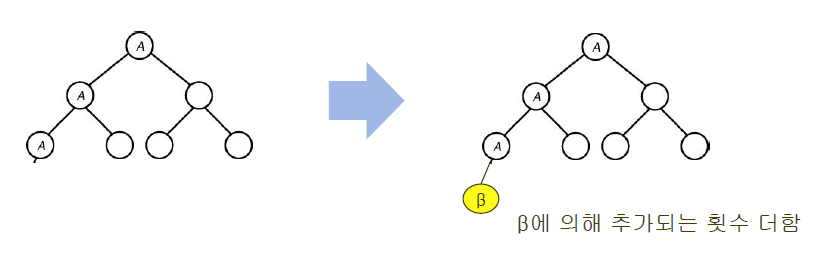
먼저 위의 트리에서 베타가 없다고 생각하고 계산해보겠습니다.
siftup 횟수를 모두 더하는 과정을 전개합니다. (S)
그리고 2를 곱한 후에 다시 전개합니다. (2S)
2S-S를 하게 되면 S가 나옵니다. 그 결과 S = n lg n - 2n + 2가 나오게 됩니다. (d = lg n이기 때문에 2^d = n입니다)
만약 여기서 새로운 노드가 하나 포함되어 d level에 추가가 되었다면 위에서 계산한 대로 lg n의 비교횟수가 추가됩니다.
그렇다면 비교 횟수는 (n+1) * lg n - 2n + 2가 됩니다.
즉 O(n lg n)만큼의 시간이 필요하게 되는 것이죠.

두 번째 방법은 모든 데이터를 트리에 넣은 상태에서 heap을 구성하는 방법입니다.
이미 모든 데이터가 들어가 있기 때문에 siftup을 할 필요 없이 각 depth(level)별로 siftdown을 하면 됩니다.

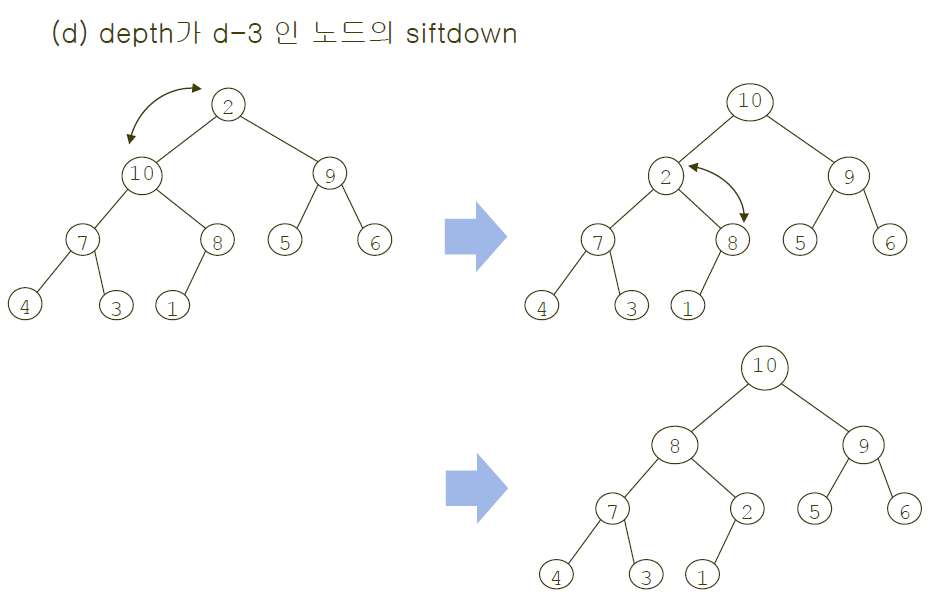
첫 번째 방법과 동일하게 최악의 경우 시간복잡도를 분석하겠습니다.
입력의 총 크기는 n이고, 2^k개만큼의 키가 있다고 가정합니다.
d를 트리의 깊이라고 하면 d = lg n이 됩니다.
이 때 d의 깊이를 가진 마디는 정확히 1개이고 그 마디는 d개의 부모노드를 가집니다.
이번에는 반대로 siftdown의 횟수를 계산합니다.
root(depth = 0)는 d-1까지만 있다고 생각할 때 최대 d-1번까지 siftdown될 수 있습니다.
그리고 한 단계씩 내려가면서 이 최대 횟수는 하나씩 줄어들게 되어서 마지막 depth(level)에서는 더 이상 siftdown을 못하게 됩니다.
그런데 만약 d라는 새로운 depth가 등장하게 되면 각 depth에서 siftdown의 최대 횟수가 1씩 증가하게 됩니다.
즉 추가적으로 d = lg n만큼의 횟수가 증가하는 것이죠.

같은 방식으로 2S-S를 통해 S를 구합니다. 그러면 S는 n lg n - 2n + 2가 나옵니다.
∑(2^j)는 두 번째 줄에서 n-1로 구할 수 있었습니다.
우리가 원하는 총 siftdown 횟수는 위에서 구한 두 식을 그대로 첫 줄의 총 siftdown 횟수 식에 넣어주면 됩니다.
그러면 (d - 1)(n - 1) - (n lg n - 2n + 2)가 되는데,
이것은 최종적으로 n - lg n - 1이 됩니다.
만약 d의 깊이를 가진 마디가 추가적으로 1개 생긴다면 d = lg n만큼의 siftdown 횟수가 추가되므로 총 횟수는 n-1이 됩니다.
그리고 한 번의 siftdown에서는 2번의 키 비교가 필요(자식이 2명이니까!)하기 때문에 비교 횟수는 2(n-1)이 됩니다.
결과적으로 시간복잡도는 O(n)이 됩니다. 첫 번째 방법에 비해서 효율적입니다!
(중요한 것은 makeheap 함수가 O(n)의 시간복잡도를 가지는 것이지 힙정렬 알고리즘이 O(n)의 시간복잡도를 가지는 것이 아니라는 것입니다!


그렇다면 힙정렬 알고리즘의 시간복잡도는 어떻게 될까요?
우선 makeheap에서 최대 O(n)까지 줄일 수 있었습니다.
나머지 작업인 removekeys의 시간복잡도를 구해야 힙정렬 알고리즘의 완벽한 시간복잡도를 알 수 있겠네요.

removekeys는 root에 위치한 요소를 삭제하고 마지막 요소가 맨 위로 올라간 후에 siftdown되는 형태로 진행됩니다.
요소가 지워지고 난 뒤 남은 요소들로 완전이진트리를 구성한 후에 siftdown되기 때문에 위에서 살펴본 siftdown에서 1개의 요소가 더 여유가 생기게 됩니다.
아래 그림에서는 5번의 removekeys가 일어날 때 각 요소들이 어떻게 움직이는 지에 대한 내용을 담고 있습니다.
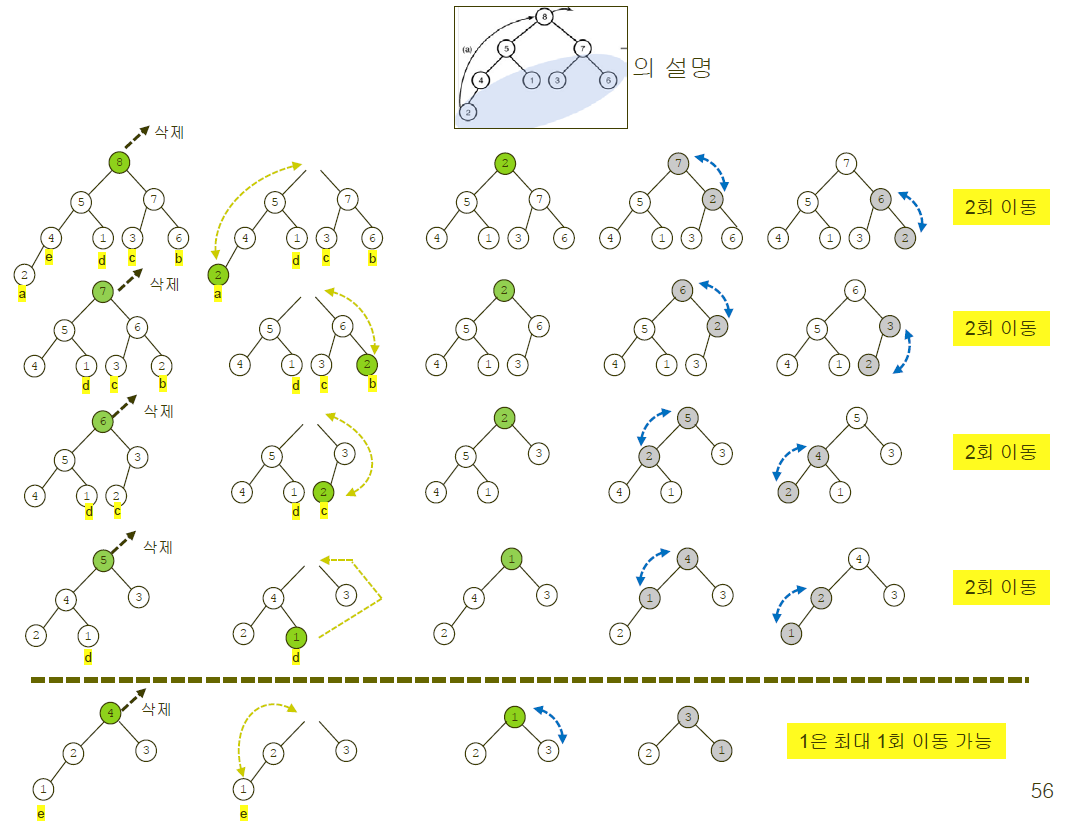
수학적으로 계산해보겠습니다.
n = 2^k라고 가정합시다. 만약 n이 8이라면 d = lg 8 = 3이 됩니다. 위의 힙 사진과 동일하게 8개의 요소를 가졌다고 생각합시다.
처음 4개의 키를 제거하는데 siftdown이 2번 발생했고, 그 다음 2개를 제거하는 데는 siftdown이 1번 발생합니다. 남은 2개를 제거하는 데는 siftdown이 발생하지 않습니다.
따라서 총 sift 횟수는 0(2) + 1(2) + 2(4) + 3(8) + ... 이런 식으로 증가해 나갈 것입니다.
이것을 일반화시키면 아래와 같습니다.

그런데 한 번 siftdown 될 때마다 2번씩 비교(위에서 말했다시피 자식 2명과 비교해야 하니까!!)하기 때문에 실제 비교 횟수는 2n lg n - 4n + 4가 됩니다.
이제 마지막으로 makeheap과 removekey를 조합해서 만든 heapsort의 시간복잡도를 생각해보면,
키를 비교하는 총 횟수는 n이 2^k일 때
2(n-1) + 2n lg n - 4n + 4 = 2(n lg n - 2n + 1)이 됩니다.
최악의 경우는 최고차항만 생각하기 때문에, 상수까지 떼버리면 시간복잡도는 O(n lg n)이 됩니다.

힙정렬 알고리즘의 공간복잡도는 어떻게 될까요?
만약 힙을 배열로 구현한 경우에는 값의 위치만 바꿔주는 형태가 되기 때문에 제자리정렬 알고리즘이 됩니다.
그래서 공간복잡도는 O(1)이 됩니다.
지정 횟수의 경우 siftdown 될 때마다 발생하므로 대략 n lg n이 됩니다.
마지막으로 지금까지 알아본 발전된 형태의 정렬인 O(n lg n)만큼의 시간복잡도를 가진 알고리즘의 비교입니다.

아래 코드는 힙정렬을 파이썬으로 구현한 코드입니다.
makeheap의 두 번째 방법을 이용하여 구현했습니다.
주석을 달아놓았으니 이해에 도움이 되셨으면 좋겠습니다!
# 힙 정렬
import math
class Heap(object):
n=0
def __init__(self, data):
self.data=data
# heap size를 하나 줄여야 한다. 인덱스는 1부터. 인덱스의 2* 연산 가능하도록.
self.n=len(self.data)-1
def addElt(self,elt): # 요소 추가
self.n += 1
self.data.append(elt)
self.siftUp(self.n)
def siftUp(self, i): # 맨 마지막 요소를 위로 올림
while i >= 2:
j = i // 2 # 부모인덱스 찾기
if self.data[j] >= self.data[i]: # 부모값이 더 크면 종료
return
self.data[j], self.data[i] = self.data[i], self.data[j]
i = j
def siftDown(self,i): # 아래로 내려가면서 힙성질을 만족하도록 위가 더 큰 값이 가지도록 조정
siftkey = self.data[i]
parent = i
spotfound = False
while 2*parent <= self.n and not spotfound:
if 2*parent < self.n and self.data[2*parent] < self.data[2*parent+1]:
largerchild = 2*parent+1
else:
largerchild = 2*parent
if siftkey < self.data[largerchild]:
self.data[parent] = self.data[largerchild]
parent = largerchild
else:
spotfound = True
self.data[parent] = siftkey
def makeHeap2(self):
for i in range(self.n//2,0,-1):
self.siftDown(i)
def root(self): # 루트에서 키값을 추출하고 힙성질을 만족하도록 바꿔주는 코드
# 맨 앞에껄 뽑고 맨 뒤에껄 맨 앞으로 가져온다. 그 후 siftdown!
if(self.n>0):
# 추가 하였음. 힙 이 더 이상없을 때는 down 없음
keyout = self.data[1]
self.data[1] = self.data[self.n]
self.n -= 1
self.siftDown(1)
return keyout
def removeKeys(self): # 제일 큰 값 빼내기 (루트값)
a=[]
for i in range(self.n):
a.append(self.root())
return a
def heapSort2(a):
h = Heap(a)
h.makeHeap2()
return h.removeKeys()
# 인덱스를 간단히 하기 위해 처음 엘리먼트 0 추가
a=[0,11,14,2,7,6,3,9,5]
b=Heap(a)
b.makeHeap2()
print(b.data)
b.addElt(50)
print(b.data)
s=heapSort2(a)
print(s)
3. 번외 : 결정트리
지금까지 여러 정렬들을 알아봤는데, 과연 n lg n보다 빠른 정렬 알고리즘을 개발할 수는 있을까요?
키의 비교 횟수를 기준으로 Big-O를 표기한다면 더 빠른 알고리즘은 불가능합니다.
그 내용을 증명해 보도록 하겠습니다.
아래는 3개의 키값인 a, b, c를 정렬하는 알고리즘의 결정트리입니다.
결정트리는 root에서 출발하여 노드의 조건을 따라가며 leaf에 도달하는 트리를 말합니다.
그리고 leaf에 있는 요소들은 하나의 결정을 나타냅니다. 아래 트리에서는 정렬 상태를 나타냅니다.
키가 총 3개이므로 정렬 상태는 총 6가지가 나오게 되겠네요!

만약 n개의 키가 각 순열에 대해 root부터 leaf까지의 경로가 존재하는 경우 결정트리가 유효하다(vaild)고 할 수 있습니다.
이 말은 크기가 n인 어떤 입력에 대해서도 모두 정렬할 수 있다는 이야기가 되겠죠.
하지만 그 중에서도 몇몇 결정트리에서는 불필요한 비교를 하는 경우가 있습니다.
예를 들어 교환정렬(O(n^2))같은 경우를 들 수 있는데, 어떤 시점에서 비교가 이루어질 때 그 이전에 이루어졌던 비교의 결과를 알 수 없기 때문에 불필요한 비교가 발생하게 됩니다. 그래서 최적(이론상 O(n), 실제 O(n lg n))에서 멀어지는 것이죠.
만약 일관성 있는 순서로 결정을 내림으로써 불필요한 비교 없이 root에서 모든 leaf에 도달할 수 있는 경우, 이 결정트리를 가지친 결정트리라고 부릅니다.
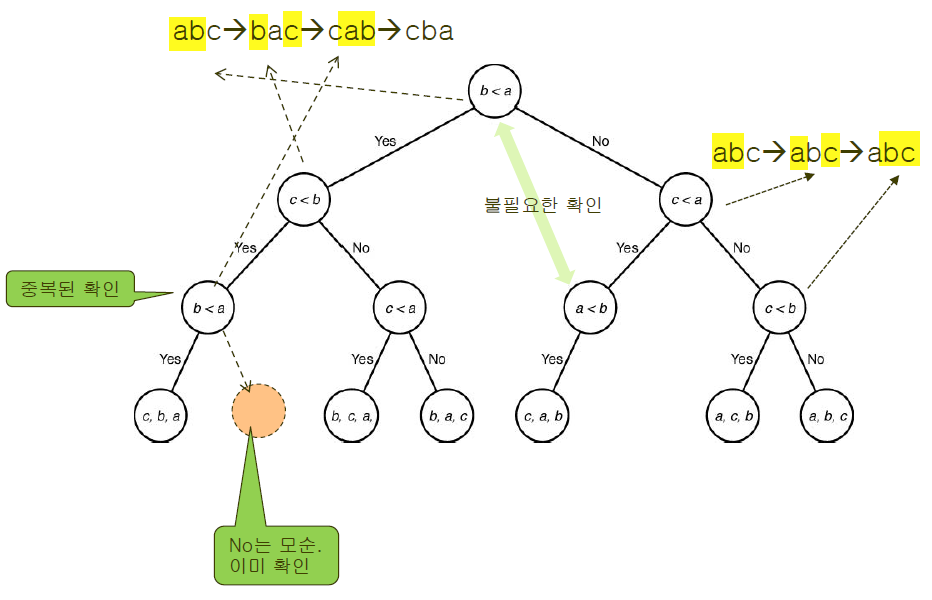
이제 O(n lg n)에 대한 증명을 위해 네 가지의 보조정리에 대해 알아보시죠!
3.0. O(n lg n) 증명 - 1
첫 번째 보조정리는 n개의 서로 다른 키를 정렬하는 결정적 알고리즘은 그에 상응하는 정확하게 n!개의 leaf를 가진 유효한 가지친 이진 결정트리가 존재한다는 것입니다.
결정적 알고리즘의 반대말은 확률적 알고리즘입니다. 우리가 보통 쓰는 알고리즘은 모두 결정적 알고리즘이라고 생각하시면 됩니다.
3.1. O(n lg n) 증명 - 2
두 번째 보조 정리는 결정트리에서 leaf에 도달할 때까지의 비교 횟수의 최댓값은 depth와 같다는 것입니다.
아래는 3의 depth를 가진 결정트리입니다. 모두 3회의 비교 후에 정렬이 되었습니다.

3.2. O(n lg n) 증명 - 3
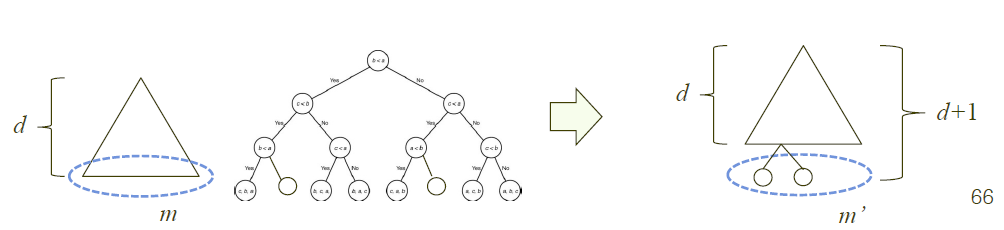
세 번째 보조정리는 이진트리의 leaf가 m개 있고, depth가 d라면 d는 (lg m)의 올림값보다는 크거나 같다는 것입니다.
물론 직관적으로 이해가 가능한 부분이지만, 귀납적으로도 증명해보겠습니다.
귀납 출발점은 d=0일 때는 2^d = 1이 됩니다. 2^d >= 1이 성립하죠?
이제 귀납을 위한 가정을 하면, 깊이가 d인 모든 이진트리에 대해 2^d >= m이 성립한다고 가정합시다.
이제 2^(d+1) >= m' 임을 보이면 되겠죠?
2^(d+1) = 2 * 2^d >= 2m >= m'이 됩니다. 각 부모마디는 최대 2개의 자식을 가지고, 1개의 자식을 가질 수도 있기 때문입니다.
결국 2^d >= m이 성립합니다. 그리고 양 변에 lg를 씌우면 d >= lg m이 됩니다. 여기서 d가 정수이기 때문에 d >= ceil(lg m)이 됩니다.
※ 정리
● 귀납 출발점 : d = 0일 때 2^d >= 1
● 귀납 가정 : 2^d >= m이 성립한다고 가정
● 귀납 절차 :
2^(d+1) >= m'이 성립한다는 것을 증명해야함
2^(d+1) = 2*2^d >= 2m (귀납가정에 의해 성립)
2m >= m' (각 부모마디는 자식마디를 최대 2개 가질 수 있으므로)
결과적으로 2^(d+1) >= m' 성립

3.3 O(n lg n) 증명 - 4
모든 양의 정수에서 lg(n!) >= n lg n - 1.45n을 만족합니다.
이것에 대한 증명은 아래 그림으로 대체합니다.
log_a(x)의 적분이 x log_a x - (x / ln a) + C라는 것만 이해하신다면 아래 내용도 쉽게 이해하실 수 있을 것이라고 생각합니다.
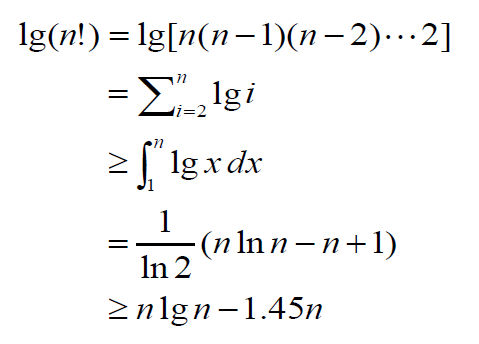
즉, n개의 서로 다른 키를 비교함으로써 정렬하는 결정적 알고리즘은 평균의 경우 최소한 (n lg n - 1.45n)를 내림한 값의 비교를 수행하게 됩니다.
합병정렬의 평균 비교 횟수가 n lg n - 1.26n이기 때문에, 합병정렬은 키를 비교하여 정렬하는 알고리즘 중에서는 거의 최적에 가깝다고 볼 수 있겠죠?
4. 기수정렬
키들의 digit의 개수가 모두 같다면, 첫 번째 digit이 같은 수끼리 모으고, 그 중에서 두 번째 digit이 같은 수끼리 모으고.. 하는 식으로 마지막까지 모으는 방법으로 각 digit을 한 번씩만 조사하면 정렬을 완료할 수 있습니다.
이 방식으로 정렬하는 알고리즘을 기수정렬(Radix sort)이라고 합니다.

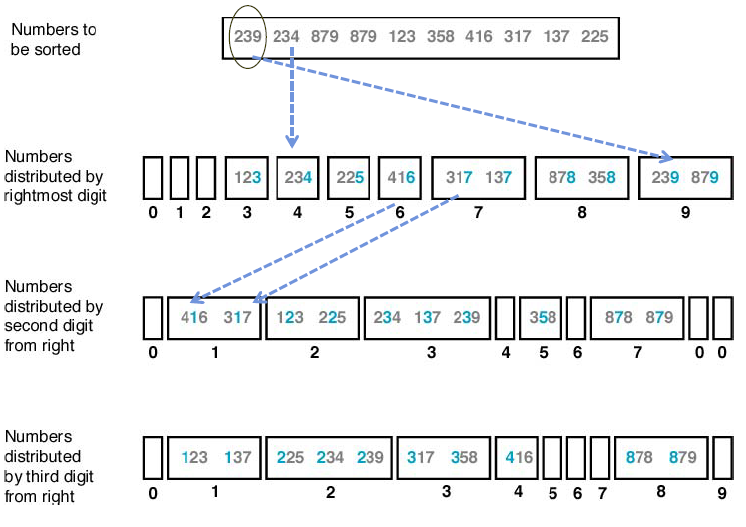
아래 코드는 오른쪽에서 왼쪽 자리 순으로 진행되는 기수정렬을 파이썬으로 구현한 함수입니다.
# 기수정렬 (오른쪽에서 왼쪽 자리 순으로 정렬)
def radix_sort(a, base=10): # base는 몇진수냐에 따라 달라진다
size = len(a) # 정렬한 요소의 사이즈
maxval = max(a) # 제일 큰 수
exp = 1 # digit 표시
while exp <= maxval: # 제일 큰 친구보다 exp가 작다면 (유의미한 digit이 남았다면)
output = [0]*size # 정렬 결과물을 담을 리스트
count = [0]*base # 특정 digit에 해당되는 값의 개수를 담은 리스트
for i in range(size): # 특정 digit에 해당되는 값을 찾기 위한 for문
count[(a[i]//exp)%base] += 1
for i in range(1,base): # 개수를 누적해서 쌓아주기 위한 for문
count[i]+=count[i-1]
for i in range(size-1,-1,-1): #
j = (a[i]//exp)%base # 값이 들어가야 하는 위치를 찾는다
output[count[j]-1] = a[i] # count에서 새로 정렬한 순서대로 output에 값을 넣는다
count[j] -= 1 # 넣었으니 값을 하나 줄인다.
for i in range(size): # 저장한 값을 a에 넣어준다
a[i]=output[i]
exp *= base # 다음 자리수를 확인
arr = [9,1,22,4,0,1,22,100,10]
radix_sort(arr)
print(arr)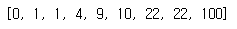
기수정렬의 시간복잡도는 각 정수를 이루는 digit의 최대 개수를 numdigits라고 하면
T(n) = numdigits(n+10)이 되고, Θ(numdigits*n)이 됩니다.
numdigits가 n과 같다면 시간복잡도가 Θ(n^2)이 됩니다. (최악의 케이스)
그러나 일반적으로 서로 다른 n개의 수가 있다면 그것을 표현하는 데 필요한 digit의 수는 lg n으로 볼 수 있습니다.
즉 일반적인 경우 시간복잡도는 O(n lg n)에 가깝게 됩니다. (최선의 경우가 O(n lg n) 입니다!)

공간복잡도는 더미리스트가 필요하기 때문에 O(n)이 필요합니다.
위 파이썬 코드에서는 count가 되겠죠? 따라서 제자리정렬이 아닙니다.
마지막으로 같은 값의 경우 서로의 위치가 바뀔 일이 없기 때문에 stable 알고리즘입니다.
5. 위상정렬
위상정렬은 i에서 j로 가는 경로가 있다면 i가 j보다 먼저 오는 정렬 방법을 의미합니다.
위상이라는 말이 어색할 수 있는데, 위상은 어떤 사물이나 다른 사물과의 관계 속에서 가지는 위치나 상태를 의미합니다. (ex 위상을 높이다)
현재 우리가 알아보고자 하는 알고리즘에서는 사물이 아니라 하나의 정점이 다른 정점과의 관계 속에서 가지는 위치나 상태를 의미하겠죠?
가장 대표적인 예시로는 대학교의 선수과목입니다. 이거 안들으면 다음 과목 못들어~와 같은 느낌이라고 이해하시면 이해가 매우 빠르게 되실 겁니다!

위와 같은 그래프가 있다면, 3과목은 1,2,4과목을 들어야 들을 수 있고, 4과목은 2과목을 들어야 들을 수 있습니다. 그리고 5과목은 3,4과목을 들어야 들을 수 있죠.
그렇다면 수업을 어떻게 들어야 할까요? 1,2과목을 듣고 나서야 4과목을 들을 수 있고, 그 다음에 3과목을 들을 수 있고 마지막으로 5과목을 들을 수 있습니다.
1-2-4-3-5 순서대로 수업을 들을 수도 있지만, 2-1-4-3-5나 2-4-1-3-5 순으로 들을 수도 있겠죠? 따라서 위상정렬은 답이 여러개 나올 수 있습니다.
위상정렬의 경우 먼저 선행 차수의 수를 담은 리스트를 만들고, 선행 차수가 0개 필요한 요소들을 stack에 저장합니다.
그리고 stack에 원소가 있다면 앞에서부터 하나씩 빼서 최종 순서를 담을 리스트에 넣고, 뺀 정점에서 갈 수 있는 모든 정점의 선행 차수의 수를 1 줄입니다.
그 이후 선행 차수의 수가 0인 요소들을 stack에 넣고, 이 과정을 stack이 빌 때까지 반복합니다.
여기서 알 수 있는 점은 맨 처음에 선행 차수의 수가 0인 요소가 없다면 위상정렬이 불가능하다는 것입니다. (이 말은 Cycle이 있으면 위상정렬이 불가능하다는 말과 같습니다.)
아래는 파이썬으로 구현한 위상정렬입니다. 다양하게 만들 수 있지만, stack을 이용하여 만들었습니다.
# 위상 정렬 (인접리스트 이용)
adj_list = {0: [2], 1: [2, 3], 2: [4], 3: [2,4], 4: []}
def topological_sort(adj_list):
s = [] # 스택
degree = [0] * len(adj_list) # 차수를 넣은 리스트 (연결된 선행 노드의 수를 담은 리스트)
answer = [] # 최종 정렬 순서를 담은 리스트
for i in range(len(adj_list)): # 인접리스트만큼 for문 돌리기
for j in range(len(adj_list)): # 인접리스트만큼 for문 돌리기
temp = adj_list[j] # 인접리스트에서 j의 키를 가진 리스트를 temp에 저장
for k in range(len(temp)): # 특정 리스트의 길이만큼 반복
if temp[k] == i: # temp 안에 i가 있다면
degree[i] += 1 # 차수 1 추가 (몇개의 노드로부터 현재 노드가 연결되는 지 파악)
print("차수 배열 : ", degree)
for i in range(len(adj_list)): # 다른 노드의 도착노드가 되지 않는 노드를 s에 삽입
if degree[i] == 0:
s.append(i)
print("초기 스택: ", s)
while s: # s에서 하나씩 빼서 answer에 삽입
node = s.pop() # pop을 통해 맨 앞 요소 제거
answer.append(node) # 뺀 것을 answer에 삽입
print("pop 된 노드: ", node) # pop된 요소 출력
for i in range(len(adj_list[node])): # node와 연결된 요소들의 degree 낮추기
idx = adj_list[node][i]
degree[idx] -= 1
if degree[idx] == 0: # 만약 더 이상 선행 노드가 없다면
s.append(idx) # 그 노드를 s에 삽입
return answer # s가 순서대로 answer에 들어가면 answer를 반환
print(topological_sort(adj_list))
위상정렬의 시간복잡도는 O(n+E)입니다. n은 정점의 개수, E는 간선의 개수입니다. E가 적다면 굉장히 빠른 알고리즘입니다.
또한 기존 요소들을 정렬해놓을 리스트가 추가로 필요하기 때문에 공간복잡도는 O(n)이고, 제자리 정렬이 아닙니다.
그래프와 정점을 이용하기 때문에 stable이 큰 의미가 없습니다. 자기 자신과 겹칠 일이 없기 때문입니다.
지금까지 계산복잡도와 정렬에 대해서 알아보았습니다.
포스팅을 2개로 쪼갰음에도 굉장히 길어져서 당황스럽습니다.. 과연 다 보시는 분이 있을까 싶기도 하고 ㅠ
필요한 부분만 원하시는 대로 가져가시면 될 것 같습니다!!
글이 길어서 잘못된 부분이 있을 수 있습니다. 혹시 발견하시면 댓글로 피드백을 달아주시면 감사하겠습니다 (_ _)
다음 주제는 계산복잡도와 검색 문제입니다. 키를 정렬할 줄 안다면, 키를 찾는 것도 크게 어렵지 않습니다!
그렇다면 다음 포스팅에서 뵙도록 하겠습니다! 감사합니다 :)








최근댓글