
이번 포스팅의 주제는 계산복잡도, 그 중에서도 정렬의 계산복잡도입니다.
어떤 알고리즘의 효율을 측정할 때는 시간복잡도와 공간복잡도를 생각합니다.
그리고 문제를 풀 때는 두 가지 케이스가 있는데,
더 효율적인 알고리즘을 찾기 위해 노력하는 케이스와 더 효율적인 알고리즘 개발이 불가능하다는 것을 증명하는 케이스가 있습니다.
예를 들면 정렬의 경우 O(n log n)보다 더 좋은 알고리즘을 개발하는 것은 불가능하다는 것이 입증되었습니다.
따라서 조금이라도 개선하기 위해서 상수적으로 더 효율적인 알고리즘을 개발하는 쪽으로 연구가 진행되고 있습니다.
그렇다면 현재 우리가 사용하는 정렬들은 어떻게 동작하며 얼마나 효율적인지 궁금해지지 않나요?
이번 포스팅에서는 계산복잡도의 개념부터 각종 정렬들을 뜯어보고 정렬들의 효율성까지도 파악해보도록 하겠습니다.
목차
0. 계산복잡도
일반적으로 계산복잡도 분석은 문제의 분석을 지칭합니다.
문제의 분석이란 어떤 문제에 대해 그 문제를 풀 수 있는 모든 알고리즘의 효율의 하한을 결정합니다.
행렬 곱셈 문제를 통해 간단하게 계산복잡도를 분석해보겠습니다.
일반적인 행렬곱셈문제는 O(n^3)이었습니다. (for문 3번)
하지만 분할정복법에서 배웠던 Strassen의 알고리즘을 사용하면 O(n^2.81)까지 줄일 수 있었습니다.
[알고리즘분석] 1. 분할정복법
이번 포스팅에서는 문제를 해결하기 쉽도록 여러 작은 부분으로 나눈 후에 각각 해결하고, 해결된 답안들을 한데 모아서 문제를 해결하는 분할정복법에 대해서 알아보도록 하겠습니다! 목차 0.
ssocoit.tistory.com
또한 행렬의 곱셈은 더욱 발전하여 Coppersmith/Winograd에 의해서 시간복잡도를 O(n^2.38)까지 줄일 수 있었습니다.
O(n^3), O(n^2.81), O(n^2.38)은 알고리즘의 분석입니다.
이 문제의 복잡도의 하한은 Ω(n^2)입니다. 그리고 이것은 문제의 분석입니다.
하지만 이는 Θ(n^2) 알고리즘이 반드시 존재하는 것을 의미하는 것은 아닙니다.
Θ(n^2)보다 더 좋은 알고리즘을 개발하는 것이 불가능하다는 것을 의미합니다.
(지금까지 크게 문제가 없었기 때문에 이전 포스팅이나 이번 포스팅에서 O와 Θ를 혼용하여 사용하였습니다만 엄밀히 말하면 O는 상한선, Ω는 하한선, Θ는 지수(딱 맞는 지수)를 의미합니다)
그렇다면 Coppersmith/Winograd의 알고리즘보다 더 빠른 알고리즘이 존재할까요? 아직은 모릅니다.
아직 현재의 하한만큼 좋은 알고리즘을 찾지 못했고, 하한이 이보다 더 큰 것도 입증하지 못했습니다.
그렇기에 현재도 계속해서 더 좋은 행렬 곱셈 연산을 위한 알고리즘이 개발 중에 있습니다.
만약 하한 분석과 알고리즘 개발이 같은 점까지 온다면 더 이상 빠른 알고리즘을 개발하는 것은 의미가 없게 되는 것입니다.
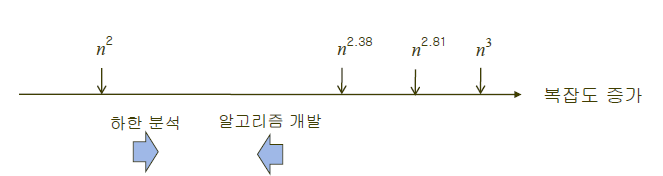
장황하게 설명했지만, 결국 우리의 목표는 복잡도 하한이 Ω(f(n))인 문제에 대해서 복잡도가 Θ(f(n))인 알고리즘을 만들어 내는 것입니다.
문제의 복잡도 하한보다 낮은 알고리즘을 만들어 내는 것은 불가능합니다.
(이유는 이미 증명이 되었기 때문입니다. 그래도 0.5. 시간복잡도와 공간복잡도 포스팅에서 설명했듯이 상수적으로 더 효율적인 알고리즘은 개발할 수 있습니다)
이제 이걸 정렬에 대입해봅시다.
교환정렬의 경우 Θ(n^2)의 시간복잡도를 가지고 있습니다.
합병정렬의 경우 Θ(n lg n)의 시간복잡도를 가지고 있습니다.
정렬 문제의 시간복잡도 하한은 Θ(n lg n)이기 때문에 정렬 문제에 있어서 알고리즘을 이 이상으로 찾는 것은 무의미할 수 있습니다.
이제 알고리즘 분석을 하는 방법에 대해서 설명하도록 하겠습니다.
이번 포스팅에서는 키의 비교횟수와 할당 횟수를 기준으로 알고리즘 분석을 할 예정입니다.
temp = s[i]
s[i] = s[j]
s[j] = temp;예를 들면 위와 같은 경우 한 번의 교환이지만 3번의 지정문(할당)이 필요합니다.
레코드의 크기가 크면 비교하는 것보다 이동하면서 레코드를 지정하는 데 걸리는 시간이 더 길어질 수 있으므로 할당 횟수도 분석에 포함합니다.
그 다음엔 분석을 위해 필요한 기초적인 정보에 대해 알아봅시다.
제자리정렬은 추가적으로 소요되는 저장장소가 상수인 것을 말합니다.
이 말은 데이터의 개수에 비례한 추가적인 저장장소가 필요하지 않다는 말과 같습니다.
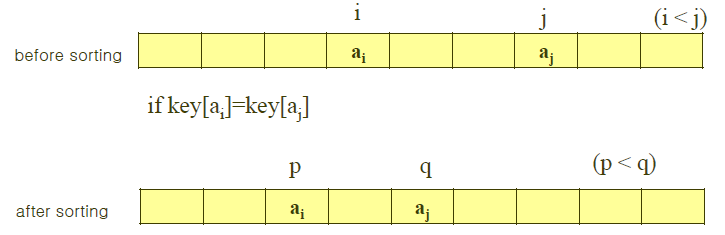
안정성(Stability)은 같은 키값을 갖는 데이터간의 정렬 전 순서가 정렬 후에도 유지되는 성질을 말합니다.
이러한 성질을 갖는 정렬발법을 stable하다라고 말하죠.
미리 말씀드리면 삽입 정렬(insertion sort), 합병 정렬(merge sort), bubble sort(거품 정렬)의 경우 stable하도록 만들 수 있습니다.
반면 퀵 정렬(quick sort), 힙 정렬(heap sort), 선택 정렬(selection sort), 교환 정렬(exchange sort)의 경우 stable하지 않습니다.
1. 삽입정렬
삽입정렬은 앞에서부터 요소를 순서대로 골라서 이미 정렬된 배열에 항목을 끼워 넣음으로써 정렬하는 알고리즘입니다.
정렬이 안된 요소들 중 제일 앞 요소를 정렬이 된 요소들 사이에서 올바른 자리에 넣어주는 방식입니다.

아래는 삽입정렬에 대한 수도코드입니다.
수도코드에 대한 설명은 위 그림으로 대체합니다.

수도코드를 이용한 파이썬 코드입니다.
위는 일반 삽입정렬이고, 아래는 객체지향 방식으로 구현한 삽입정렬입니다.
저는 삽입정렬의 원리는 알았으나 코드 동작이 이해가 안되서 조금 애를 먹었습니다.
주석을 자세하게 남겼으니 참고하세요!
# 삽입정렬
def insertionsort(n,s): # n은 값의 수, s는 값을 가진 리스트
for i in range (1,n):
x = s[i]
j = i-1 # j는 i보다는 작은 인덱스값
# i보다 작은 인덱스값은 이미 정렬이 되어있다
# 정렬이 되어있는 값 중 가장 큰 값부터 순서대로 비교
while j>=0 and s[j]>x: # j가 0보다 크거나 같고 s[i]가 s[j]보다 작으면
s[j+1] = s[j] # 한 칸씩 앞으로 땡기기
j -= 1
s[j+1] = x # 자기자리를 찾으면 그곳에 저장해둔 s[i]를 넣는다
s=[3,2,5,7,1,9,4,6,8]
n = len(s)
insertionsort(s)
print(s)
# 객체지향 삽입정렬
class List():
def __init__(self, s):
self.data = s[:]
self.n = len(s)
def insertion_sort(self):
for i in range (1,self.n):
x = self.data[i]
j = i-1 # j는 i보다는 작은 인덱스값
# i보다 작은 인덱스값은 이미 정렬이 되어있다
# 정렬이 되어있는 값 중 가장 큰 값부터 순서대로 비교
while j>=0 and self.data[j]>x: # j가 0보다 크거나 같고 s[i]가 s[j]보다 작으면
self.data[j+1] = self.data[j] # 한 칸씩 앞으로 땡기기
j -= 1
self.data[j+1] = x # 자기자리를 찾으면 그곳에 저장해둔 s[i]를 넣는다
return self.data # s를 반환한다
s=[3,2,5,7,1,9,4,6,8]
a = List(s)
print(a.insertion_sort())

이제 삽입정렬 알고리즘을 분석해보겠습니다.
먼저 최악인 경우를 생각합니다.
S[j]와 x를 비교하는 횟수를 기준으로 최악의 경우 while문에서 i-1번의 비교가 일어납니다. (완벽히 역배열로 시작하는 경우가 가장 최악입니다)
그러면 비교하는 횟수는 n(n-1)/2가 됩니다.
오른쪽 그림은 rough하게 봤을 때 정사각형의 절반만큼 비교가 일어나므로 n^2/2라고 표현한 것입니다.
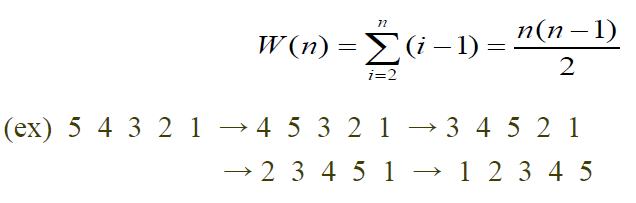

이번에는 평균인 경우의 시간복잡도 분석입니다.
i의 원래 위치가 i면 그 자리에 있으면 되기 때문에 1번만 비교하면 됩니다.
만약 있어야할 위치가 앞으로 갈수록 비교횟수가 1씩 늘어납니다.
다만 삽입할 장소의 인덱스가 맨 앞인 경우는 i-1인데, 삽입할 장소가 2일 때는 맨 앞 요소보다 큰 경우고 1일 때는 맨 앞 요소보다 작은 경우입니다. 즉 한번만 비교하면 삽입할 장소의 인덱스가 1인지 2인지 알 수 있습니다.
코드에 의한 논리적 분석으로는 인덱스 제약조건(j>=0)에 의해 j=-1이 될 수 없으므로 i-1번의 비교만 일어나게 됩니다.

정렬 후 해당 위치의 데이터가 될 확률은 1/i이기 떄문에 (어느 위치든지 위치할 확률은 모두 같습니다!) 확률을 고려하여 x를 삽입하는데 필요한 비교 횟수는 아래와 같습니다.

위 비교횟수를 i=2부터 n까지 반복한다면 아래와 같은 결과가 나옵니다.
평균이기 때문에 Area 결과값에서 또 절반이 줄은 결과가 나오네요!

위 내용을 종합해보면 시간복잡도가 O(n^2)라는 것을 확인할 수 있습니다.
할당의 경우 계속 한칸씩 땡겨가기 떄문에 최악의 경우와 평균 모두 시간복잡도와 동일하게 n^2입니다.
대신 추가적인 공간을 사용하지는 않으므로 제자리 정렬이고,
key값이 같다면 뒤에 있던 요소가 그대로 뒤에 오기 떄문에(뒤에서부터 앞으로 가는 형태라) stable 알고리즘입니다.

2. 선택정렬
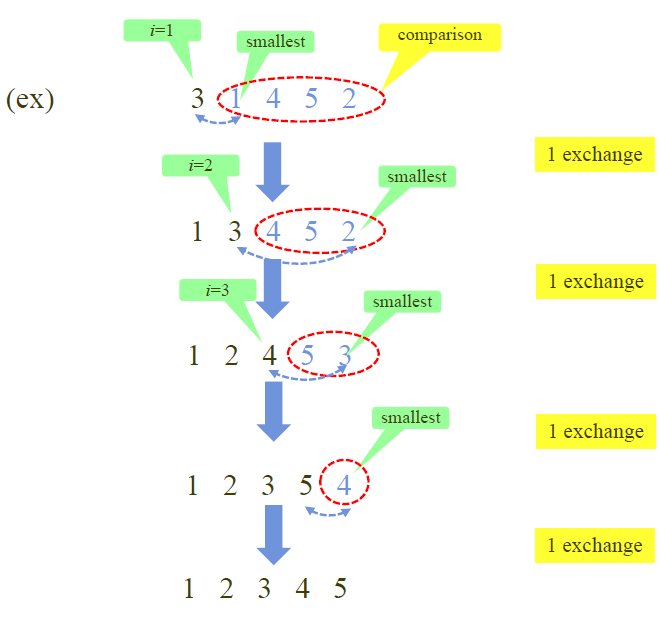
선택정렬은 앞에서 순서대로 하나씩 고른 후, 다음 인덱스부터 마지막까지 중에서 가장 작은 수를 찾아서 앞에서 고른 인덱스와 위치를 바꿔주는 방식으로 진행되는 알고리즘입니다.
아래 그림을 통해 확인하실 수 있습니다. 이해하기 쉬운 알고리즘 중 하나죠.
다음은 선택정렬의 수도코드입니다.

수도코드를 이용하여 선택정렬을 파이썬으로 구현했습니다.
이번에도 일반 선택정렬과 객체지향 방식 선택정렬 두 가지 케이스로 만들었습니다.
# 선택정렬
def selection_sort(n,s):
for i in range(0,n-1): # 인덱스는 앞에서부터 순서대로, 맨 마지막은 안해도되니 n-1까지
smallest = i
for j in range(i+1, n): # i인덱스의 다음부터 끝까지 최솟값 찾기
if s[j] < s[smallest]:
smallest = j
s[i], s[smallest] = s[smallest], s[i] # 바꿔주기
s=[3,2,5,7,1,9,4,6,8]
n = len(s)
selection_sort(n,s)
print(s)# 객체지향 선택정렬
class List():
def __init__(self, s):
self.data = s[:]
self.n = len(s)
def selection_sort(self):
for i in range (0,self.n-1):
smallest = i
for j in range(i+1, n): # i인덱스의 다음부터 끝까지 최솟값 찾기
if self.data[j] < self.data[smallest]:
smallest = j
self.data[i], self.data[smallest] = self.data[smallest], self.data[i] # 바꿔주기
return self.data # s를 반환한다
s=[3,2,5,7,1,9,4,6,8]
a = List(s)
print(a.selection_sort())
선택정렬의 경우 i가 1일 때 비교횟수는 n-1, i가 2일 때 비교횟수는 n-2 ... i가 n-1일 때 비교횟수는 1이 됩니다.
이를 모두 합하면 T(n) = n(n-1)/2가 되죠. 즉 O(n^2)이 됩니다.
지정하는 횟수를 기준으로 하면 1번 교환에 3번 지정하기 때문에 T(n) = 3(n-1)이 됩니다. 즉 할당 횟수는 3n이 됩니다.
그리고 n에 비례하여 증가하는 추가적으로 사용하는 공간이 없으므로 제자리 정렬입니다.
다만 별 다른 확인 절차 없이 값의 순서를 바꾸기 때문에 unstable 알고리즘입니다.

3. 교환정렬
교환정렬은 특정 인덱스의 키와 나머지 키를 비교하여 자신보다 낮은 경우 교환하여 가장 작은 키를 순서대로 위치시키는 알고리즘입니다.
첫 번째 요소를 선택하고, 뒤로 가면서 그 요소보다 작은 요소가 발견되면 자리를 바꿉니다.
자리를 바꾸고 나서 새롭게 그 자리에 들어가게 된 요소와 다음 요소들을 비교해서 더 작은게 있다면 다시 바꿔줍니다.
이것을 맨 끝까지 진행하고 나면 다음 단계에서는 두 번째 요소를 선택하고 세 번째 요소부터 다시 비교를 시작합니다.
이것을 끝까지 진행하면 순서대로 정렬됩니다.

아래는 교환정렬의 수도코드입니다. 순서대로 비교한 후에 교환만 해주면 되기 떄문에 아주 간단합니다.

파이썬으로 수도코드를 구현했습니다. 수도코드를 거의 그대로 가져와서 사용해도 될 정도로 간단합니다.
# 교환정렬
def exchange_sort(n,s):
for i in range(n-1):
for j in range(i+1, n):
if s[j] < s[i]:
s[i], s[j] = s[j], s[i]
s=[3,2,5,7,1,9,4,6,8]
n = len(s)
exchange_sort(n,s)
print(s)# 객체지향 교환정렬
class List():
def __init__(self, s):
self.data = s[:]
self.n = len(s)
def exchange_sort(self):
for i in range(self.n-1):
for j in range(i+1, self.n):
if self.data[j] < self.data[i]:
self.data[i], self.data[j] = self.data[j], self.data[i]
return self.data # s를 반환한다
s=[3,2,5,7,1,9,4,6,8]
a = List(s)
print(a.exchange_sort())
교환정렬도 최악의 경우 매번 비교합니다. 특히 한번의 교환에 3번씩 할당하므로, 할당의 수는 교환의 수 * 3이 됩니다.
따라서 시간복잡도는 O(n^2), 할당 횟수는 3n^2 / 2가 됩니다.
다행히 추가적으로 필요한 저장공간은 없기 때문에 제자리 정렬입니다만
단순비교 후 최솟값과 변경하는 알고리즘이기 때문에 unstable합니다.

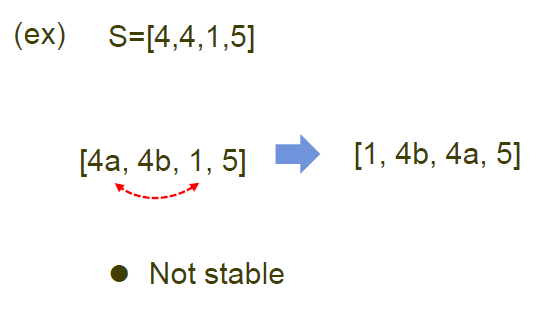
4. 거품정렬
거품정렬은 버블정렬(bubble sort)라고도 불리며, 기존 알고리즘들이 앞에서부터 정렬된 것과는 다르게 뒤에서부터 정렬됩니다. (큰 요소부터 정렬!!)
첫 번째 단계에는 첫 번째 자료와 두 번째 자료를 비교해서 큰 친구를 뒤로 보내고, 그 다음에는 두 번째 자료와 세 번째 자료를 비교해서 큰 친구를 뒤로 보내고, ... 이걸 끝까지 반복하면 제일 큰 친구가 맨 뒤로 가게 됩니다.
두 번째 단계에는 맨 마지막 자료는 정렬에서 제외되고, 세 번째 단계에서는 그 다음 자료가 정렬에서 제외되고, 이것이 반복되어서 맨 뒤부터 차례대로 정렬됩니다.

수도코드는 교환정렬의 수도코드와 거의 유사합니다.

수도코드를 파이썬으로 구현했습니다. 역시 간단하기에 별다른 설명은 생략하고 넘어가도록 하겠습니다.
# 거품정렬
def bubble_sort(n,s):
for i in range(n-1,-1,-1): # n-1부터 0까지 반복
for j in range(1,i):
if s[j-1] > s[j]:
s[j-1], s[j] = s[j], s[j-1]
s=[3,2,5,7,1,9,4,6,8]
n = len(s)
exchange_sort(n,s)
print(s)# 객체지향 거품정렬
class List():
def __init__(self, s):
self.data = s[:]
self.n = len(s)
def bubble_sort(self):
for i in range(self.n-1,-1,-1): # n-1부터 0까지 반복
for j in range(1,i):
if self.data[j-1] > self.data[j]:
self.data[j-1], self.data[j] = self.data[j], self.data[j-1]
return self.data # s를 반환한다
s=[3,2,5,7,1,9,4,6,8]
a = List(s)
print(a.bubble_sort())
교환정렬과 거의 유사한 알고리즘인만큼, 시간복잡도와 할당 횟수 역시 동일합니다.
시간복잡도는 O(n^2)이고, 똑같이 한 비교당 할당을 3번 하기 때문에 비교 횟수는 3n^2 / 2입니다.
추가적인 저장공간을 필요로 하지 않기 때문에 제자리 정렬이고
양 옆끼리만 비교하기 때문에 같은 키값을 가진 요소가 순서가 서로 변동될 일이 없어서 stable한 알고리즘입니다.

5. 정리 및 부가설명

O(n^2)시간이 걸리는 단순정렬 4가지에 대해서 알아봤습니다.
위 표는 지금까지 공부한 내용을 정리한 표입니다.
그렇다면 각 정렬별로 특징에 대해서 알아보겠습니다.
- 삽입정렬은 어느 정도 정렬된 데이터에 대해서는 추가적인 할당작업을 최소화할 수 있어서 빠르게 수행될 수 있습니다.
- 위 표의 비교횟수와 지정횟수를 보면 삽입정렬의 경우 교환정렬/거품정렬보다는 항상 빠르게 수행됩니다. (삽입정렬의 Worst 비교횟수와 선택정렬의 비교횟수가 같습니다!)
- 하지만 선택정렬이 교환정렬보다 빠른지 여부는 정확히 알 수 없습니다. 하지만 일반적으로 지정횟수에서 지수가 1인 선택정렬이 더 빠르다고 볼 수 있습니다.
- 만약 입력이 이미 정렬되어 있는 상태로 주어질 경우 선택정렬은 지정하는 과정이 반드시 필요하지만 교환정렬은 지정하는 과정이 필요하지 않으므로 교환정렬이 더 빠릅니다.
- n의 크기가 크고, 키의 크기가 큰 자료구조라면 지정하는 데에 시간이 많이 걸리기 때문에 선택정렬 알고리즘이 삽입정렬 알고리즘보다 더 빠를 수 있습니다.
추가로 역에 대해서 말씀드리겠습니다.
n개의 키가 1부터 n까지의 양의 정수라고 하면 n개의 양수는 n!개의 순열이 존재합니다. (n개의 양수가 나열되는 경우의 수가 n!가지라는 말과 같습니다)
역은 인덱스는 더 작은데, 값은 더 큰 경우를 의미합니다.
만약 [3, 2, 4, 1, 6, 5]라는 순열이 있다면, 이 순열에는 (3,2), (3,1), (2,1), (4,1), (6,5) 총 5개의 역이 존재합니다.
키를 비교하여 n개의 서로 다른 키를 정렬하고 한 번 비교한 후에 최대한 하나의 역 만을 제거하는 알고리즘은 최악의 경우 n(n-1) / 2 만큼의 비교를 수행하고, 평균적으로 n(n-1)/4만큼의 비교를 수행한다는 것을 확인했습니다.
이 비교 횟수는 이미 위에서 증명했고, 한 번 비교할 때 역 관계에 있는 두 요소를 서로 바꿔주면 하나의 역이 제거됩니다.
교환, 삽입, 선택, 버블정렬의 경우 한 번 비교할 때 하나의 역만을 제거할 수 있으므로 시간복잡도는 O(n^2)보다 좋을 수 없습니다.
아래는 4 3 2 1 순으로 완전히 역배열로 되어있는 경우 첫 요소와 두 번째 요소를 비교하고 역을 제거한 뒤에 다시 역을 세어봤을 때 어떻게 변화하는지를 나타내는 표입니다.
역 1개를 제거했을 때 모두 역이 5개 남아있는 것을 볼 수 있습니다.

이번 포스팅에서 모든 내용을 다 정리한다면 정렬 파트가 너무 길어질 것 같아 중간에 한 번 끊었다 가도록 하겠습니다.
다음 포스팅에서는 합병정렬, 퀵정렬, 힙정렬, 기수정렬 등 기존 정렬 방법에서 더 효율적으로 정렬하기 위해서 등장한 방법들에 대해 알아보도록 하겠습니다!
오늘도 읽어주셔서 감사합니다 :)








최근댓글