
안녕하세요! 오늘도 코딩하는 경제학도 쏘코입니다.
오늘 중점적으로 살펴볼 내용은 C++ 카테고리에서 다룬 적 있는 연관 컨테이너(Associative Container)인 set과 map입니다. 그리고 변경할 수 없는 타입인 tuple도 알아보려고 합니다!
(연관 컨테이너는 데이터를 일정 규칙에 따라 조직화하여 저장하고 관리하는 컨테이너입니다!
이런 컨테이너들에서 템플릿을 어떻게 사용하는 지까지 확인하시면 되겠습니다!
목차
0. Map
연관 컨테이너를 이해하는데에 있어서 set보다는 map이 더 적절하기 때문에 map부터 알아보도록 하겠습니다.
map은 key값과 value값이 쌍으로 저장되는 연관 컨테이너입니다.
map의 몇 가지 특징을 알아보면 아래와 같습니다.
- key값은 중복이 되지 않는다는 특성을 가집니다. (Unique key)
- 삽입되면서 동시에 정렬됩니다.
- 균형 이진 트리 구조로 저장이 되어있습니다.
- 동적할당됩니다. (값을 넣을 때 필요한 메모리를 가져옵니다)
우리가 쉽게 이해할 수 있는 예시로 배열 a의 i번째 요소인 a[i]를 사용해보겠습니다.
배열 a[i]에서 i는 인덱스(Index), a[i]는 요소(Element)입니다.
하지만 map의 a[i]에서 i는 key값이 되고, a[i]는 value값이 됩니다!

배열에서는 a[i]에서 i는 반드시 정수값이 들어가야 하는데, map에서는 i에 다른 값이 들어갈 수 있습니다!
key값이 반드시 int일 필요는 없으니까요!
map을 사용하기 위해서는 전처리 과정에서 먼저 map을 include해야 합니다.
실제로 사용할 때에는 map<key, value> 맵이름과 같은 형식으로 사용할 수 있습니다.
map<int, char> m1;
map<char, double> m2;
만약 바로 초기화 하고 싶다면 {{key1, value1}, {key2, value2}} 형식을 맵이름 뒤에 붙여주면 됩니다!
아래 예시에서는 4개의 key/value값이 container라는 map타입 객체에 저장되고,
[]operator 사이에 key값을 넣어서 value값을 불러왔습니다.

0.0. unordered_map
map의 모든 특성을 가지지만, 정렬만 되지 않는 컨테이너가 unordered_map입니다.
(여기서는 설명하지 않지만, set도 unordered_set이 있습니다!)
아래 예시에서는 key값을 기준으로 오름차순 정렬이 된 상태로 출력되는 map과
정렬이 되지 않아서 입력 순서대로 출력되는 unordered_map의 차이를 보실 수 있습니다.

map에 대한 더 자세한 내용은 아래 STL Map 사용설명서 글을 참조하시면 도움이 되실겁니다 ㅎㅎㅎ
[C++ STL] Map 사용설명서
안녕하세요! 코딩하는 경제학도 쏘코입니다. 작년 2학기에 자료구조 수업을 들으면서 여러 자료구조를 짜면서 STL의 위대함을 느꼈습니다. 여러 알고리즘을 보다보니 다양한 STL들에 대해서도 간
ssocoit.tistory.com
1. Set
set은 key값과 value값이 일치하는 연관 컨테이너입니다.
key값과 value값이 하나로 합쳐진 map이라고 보시면 됩니다!
위에서 설명한 map의 특징을 모두 가진다는 말이 되겠죠?
set을 사용하기 위해서는 전처리 과정에 #include <set>을 넣어주어야 합니다.
그리고 사용할 때에는 set<key> 변수이름과 같은 형식으로 사용할 수 있습니다.
set<int> s1;
set<string> s2;
set의 경우 배열처럼 set<int> S{요소1, 요소2} 와 같이 선언과 초기화를 동시에 할 수 있습니다.
만약 set에 10, 3, 7, 2, 7, 11, 3을 넣는다면 set에서는 중복한 key값을 가지지 않기 때문에 10, 3, 7, 2, 11이 담기게 됩니다.
그리고 자동으로 정렬이 된다고 했죠?
for문을 통해 출력하면 2, 3, 7, 10, 11이 출력됩니다.
set에 5, 4, 5, 2, 4, 9를 넣는다면 어떻게 될까요?
중복을 제거하고 정렬를 마치면 2, 4, 5, 9가 출력됩니다!
set을 생성할 때 어떤 자료형을 key값으로 할 지 꺽쇠에 넣었죠?
템플릿을 사용하면 자신이 원하는 타입의 자료를 set에 넣을 수 있습니다.
아래 예시에서는 MyClass라는 구조체를 넣었습니다.
그리고 정렬과 출력을 위해서 operator<, ostream의 operator<<를 연산자 오버로딩했습니다.

1.0. set = 집합
set을 번역하면 집합입니다.
괜히 이름만 집합이 아니라, 우리가 수학시간이 배웠던 집합의 개념들을 set에 적용할 수 있습니다!
아래 예시는 교집합과 합집합을 구현한 코드입니다.
<algorithm>과 <iterator>를 전처리 과정에서 추가해줍니다.
교집합의 경우 algorithm 라이브러리의 set_intersection을 사용하고,
합집합의 경우 iterator 라이브러리의 insert_iterator를 사용합니다.
교집합은 서로 비교하면서 유무를 파악해야 하지만, 합집합은 중복제거와 자동정렬의 특성때문에 새로운 집합에 추가만 해 주면 됩니다.
(예시에서 operator<< 부분이 왜 이렇게 복잡해졌냐면.. 맨 끝의 콤마를 제거해서 깔끔하게 만들어주기 위해서입니다! 그것만 아니면 그냥 for문 한번 돌려서 깔끔하게 만들면 되는데..)


vector에 결과값을 저장하는 코드를 짜면 아래와 같습니다.
거의 똑같지만 하나 다른 점이 있다면 set에서는 자동으로 정렬되기 때문에 기존에 있는 값과 관계 없이 어디에 넣어도 상관이 없어서 inserter를 사용했지만,
vector에서는 자동으로 정렬이 되지 않기 때문에 문제가 발생할 수 있습니다.
만약 {0}이 이미 들어가 있는 상태로 초기화되었고,
원래 back_inserter가 들어갔던 자리에 inserter(v1_union_v2, std::begin(v1_union_v2)); 를 쓰게 된다면
0이 맨 뒤로 가버려서 정렬이 완벽하게 되지 않은 상태로 출력이 됩니다.
그렇기 때문에 0을 맨 앞에 보내주기 위해서 back_inserter를 써 준 것입니다.

만약 애매한 값이 들어있다면 어떻게 될까요?
8이 이미 들어있다고 생각하면, inserter를 이용하여 begin에 넣든, end에 넣든 정렬이 되지 않은 상태로 출력이 될 것입니다.
이런 상황에서는 set을 쓰거나 따로 vector를 정렬하는 방법을 사용해야겠죠!

아래 코드는 비트연산자를 연산자 오버로딩을 통해 편하게 합집합과 교집합을 사용할 수 있도록 만들어 놓은 예시입니다.
&는 AND이기 때문에 둘 다 있어야 하는 교집합, |는 OR이기 때문에 둘 중 하나만 있어도 되는 합집합이 됩니다.

set에 대한 더 자세한 내용은 아래 Set 사용설명서 글에 더 자세하게 나와있습니다!
[C++ STL] Set 사용설명서
안녕하세요! 코딩하는 경제학도 쏘코입니다. 지난 게시물에서 Map에 대해 다룬 적이 있었죠? 이번 Set은 Map과 굉장히 유사한 친구입니다. 오히려 Map보다 더 단순화된 형태이죠. (Set을 이해하면 Map
ssocoit.tistory.com
2. Tuple
만약 서로 다른 형태의 요소들을 하나로 묶어서 저장하고 싶다면 그럴 때 사용할 수 있는 게 바로 튜플입니다.
튜플(Tuple)은 고정된 크기를 가지고, 다른 타입의 값을 묶어서 저장할 수 있는 컨테이너입니다.
튜플의 사용 방법은 set과 거의 동일합니다.
tuple<자료형1, 자료형2, ...> 튜플명{자료1, 자료2, ...};
형태로 사용할 수 있습니다.
아래는 string, int, double형의 자료를 동시에 저장하는 t1이라는 객체를 만든 예입니다.
이 객체가 가진 자료들에 tie함수를 이용해서 이름을 붙여서 사용할 수 있습니다.
(실제로는 call by reference로 요소들을 가져와서 ()내의 요소들의 값을 변경시키는 역할을 합니다)

make_tuple함수를 이용해도 튜플을 만들 수 있습니다.
(tie가 call by reference로 데이터를 가져왔다면, make_tuple은 call by value로 값을 가져와서 튜플을 만듭니다)
그리고 get함수, get<index>(튜플명)을 통해서 튜플의 요소를 인덱스에 맞게 가져올 수도 있습니다.

지금까지 내용을 조합하면 벡터에 튜플을 저장해서 요소를 가져오는 아래와 같은 프로그램도 만들 수 있습니다!
t를 reference type으로 가져왔기 때문에 for문을 돌 때마다 요소들이 바뀌어서 저장되고, 마지막에 출력됩니다.

TMI : Visual Studio에서 C++ 언어 표준을 C++17 이후로 바꾼다면 아래와 같은 형식으로 조금 더 편하게 사용할 수도 있습니다!

2.1 Pair
pair는 2개의 요소를 가진 tuple입니다.
tuple의 특성을 모두 가지고 있습니다.
get함수, make_pair함수, tie함수 모두 사용이 가능합니다.
(Visual Studio 2019에서는 #include <tuple>을 하지 않아도 사용이 가능했습니다!)
make_pair(자료1, 자료2); 형태로 만들거나
pair<자료형1, 자료형2> 페어명{자료1, 자료2}; 형태로 만들 수 있습니다.
2개가 한 쌍이기 때문에 key와 value값을 가진 map에서 많이 사용됩니다.
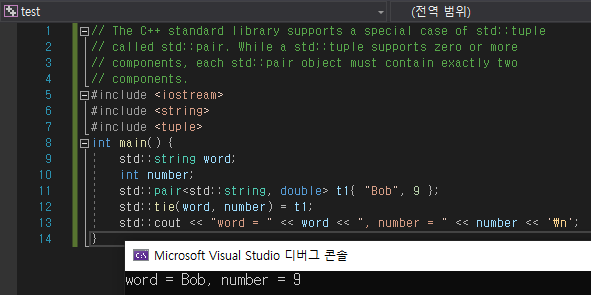
기존 tuple과의 차이점이라면, 단 2개의 요소를 가지고 있기 때문에 first와 second를 이용하여 손쉽게 pair의 요소에 접근할 수 있습니다.
당연히 auto[wrd, nbr] = t3의 기존 형태로도 사용할 수 있습니다.

3. 부록 : Counting & Memoization
3.0. 음수의 개수 세기
아래 예제는 pair를 이용해서 벡터의 요소 중에서 음수가 몇 개이고 음수가 아닌 수가 몇 개인지를 세는 프로그램입니다.
먼저 짝수와 홀수의 개수를 담을 변수를 2개 만들어줍니다.
그리고 벡터의 각 요소를 불러와서 0보다 작으면 음수 개수를 1 올리고, 그 외의 경우에는 음수가 아닌 수의 개수를 1 올립니다.
이 값을 make_pair()함수를 이용하여 반환한 후에 출력할 때에는 first와 second를 이용하여 출력하는 프로그램입니다.

3.1. 단어수 세기
이번엔 어떤 파일에서 단어를 세는 프로그램입니다.
main함수에 매개변수가 있는데, 보통 vscode에서 잘 사용하지 않지만 여기 나와있기 때문에 간단하게 설명드리면
int argc는 메인 함수에 전달되는 정보의 개수이고, char* argv[]는 메인함수에 전달되는 실질적인 정보입니다.
argv[] 첫 문자열은 프로그램의 실행경로로 고정이 되어있습니다.
argv[0]에는 경로가 들어있고, argv[1]에는 파일명이 들어있게 되는 것이죠!
프로그램을 실행할 때 파일명을 받아오기 위해 filename에 argv[1]을 저장합니다.
중요한 부분은 이제부터입니다!
counters라는 map형태의 객체를 하나 만들어줍니다.
counters에는 글자가 들어갈 string부분과 등장 횟수가 들어갈 int가 들어가야겠죠?
이제 정상적으로 파일을 읽어왔다면 transform함수를 통해 소문자를 모두 대문자로 바꿔주고,
순서대로 단어를 읽으며 counters에 저장합니다.
만약 처음으로 등장한 단어라면 counters[word]++때문에 그 단어의 value는 1로 저장됩니다.
1번 이상 등장한 단어라면 그 단어의 등장 횟수에 +1이 되겠죠?
이런 방식으로 다 저장하고, 마지막에 key값(단어)과 value값(등장횟수)를 출력합니다.
실제로 문서를 넣어서 확인하지 않더라도, 개념만 이해해도 충분합니다!
(알고리즘 문제에서 꽤 자주 쓰일 수 있기 때문에 잘 알아두시면 좋습니다!!)

3.2. 메모이제이션
메모이제이션(Memoization)은 동일한 계산을 반복해야 할 때 이전에 계산한 값을 저장하여 동일한 계산의 반복수행을 줄여 실행속도를 빠르게 할 수 있도록 도와주는 기술입니다.
피보나치 수열은 이전 두 요소를 더해서 만들어집니다.
그렇기 때문에 이전 요소들을 따로 저장해 놓는다면, 매번 계산할 필요 없이 그대로 가져와서 사용하면 되겠죠?
피보나치 수열은 아래 그림과 같이 key와 value로 나눌 수 있습니다.
이것을 map 형식으로 나타내면 {0,0}, {1,1}, {2,1}, {3,2}, {4,3}, {5,5}, {6,8}과 같이 나타낼 수 있겠죠!

아래 예제에서는 static 지역변수를 사용해서 ans를 전역변수처럼 만들어주었습니다.
이제 아직 계산하지 않은 값(n > 1인데 ans에 값이 없는 경우)이 들어오면 이전 요소 2개를 더해서 계산해줍니다.
그리고 그 계산한 값을 ans에 저장하고 반환합니다.
이런 식으로 이전 값들을 ans에 미리 저장해두면 이미 계산된 케이스는 ans라는 map에서 가져오기만 하면 되기 때문에 매우 빠르고 간편합니다!

지금까지 템플릿을 이용하여 다양한 자료형을 쉽게 정리할 수 있는 케이스들에 대해서 알아봤습니다.
다 작성하고 보니까 거의 STL 포스팅이 되버렸네요..?!
복습하는 차원에서 굉장히 좋았던 그런 포스팅이었습니다.
아마 다음 포스팅이 마지막 포스팅이 될 것 같습니다!
마지막까지 끝까지 달려봅시다! 파이팅!!! 😄
오늘도 읽어주셔서 감사합니다 :)








최근댓글