
안녕하세요! 코딩하는 경제학도 쏘코입니다.
이번 포스팅에서는 여러 개의 데이터를 한번에 관리할 수 있는 vector, array에 대해 알아보겠습니다!
목차
0. Array
0.0. 배열의 기초
배열(Array)은 같은 종류의 자료를 연속적인 메모리에 보관하는 정적인 자료구조입니다.
가장 큰 특징은 한번 선언하면 중간에 원소의 개수를 변경할 수 없습니다.
이것은 단점이 될 수도 있지만, 메모리 사용에 있어서는 미리 할당을 해놓는다는 측면에서 좋을 때도 있습니다.
일반적인 배열을 선언할 때에는 배열 안에 들어갈 자료형, 배열명, 그리고 크기를 적어줍니다.
크기의 경우 [ ] 안에 적어줍니다.
만약 배열 안의 요소들을 한번에 초기화 해주고 싶다면 = {요소1, 요소2, ...} 와 같은 형식으로 만들어줄 수 있습니다.
이렇게 초기화를 해 준 경우 리스트의 크기를 적지 않아도 알아서 요소의 개수만큼의 리스트를 생성합니다.
그리고 만든 배열에 접근할 때는 배열명[인덱스]를 통해 할 수 있습니다.
인덱스가 0부터 시작하기 때문에, 10이라는 크기의 인덱스를 만든다면 0부터 9까지의 인덱스가 만들어지겠죠?

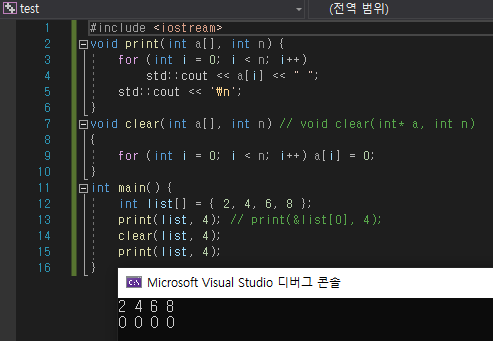
list라는 이름의 배열을 하나 만들어서 2, 4, 6, 8 원소를 가지도록 초기화를 했습니다.
각각 출력과 모든 원소를 초기화를 담당하는 print와 clear 함수를 만들어서 배열의 작동을 확인할 수 있습니다.
이전에 변수의 주소값은 데이터의 맨 앞을 가리킨다고 말한 적이 있죠?
배열의 주소값도 별도의 인덱스 설정이 없다면 배열의 맨 앞을 가리키는 주소값이 됩니다.
포인터 변수 p가 a, 아니면 &a[0](a의 주소)를 가진다면, p에다가 1을 더해지면 주소값이 1 추가됩니다.
이 말은 배열의 다음 요소를 가리킨다는 말과 같습니다.

아래와 같이 포인터 변수를 이용해서 다양하게 써 먹을 수 있습니다.

포인터 변수가 작동하는 모습을 그림으로 표현했습니다.
p를 처음 선언했을 때는 아무것도 가리키지 않다가, a를 설정하면 a배열의 맨 앞을 가리키게 되고,
p에 1을 더하면 배열의 다음 요소를 가리키게 되고,
*p를 통해 a[1]에 직접 접근해서 요소를 변경할 수 있습니다.

포인터 변수를 이용하여 프린트 함수를 만들어서 사용할 수도 있습니다.
요소의 인덱스를 포인터로 대체하기 때문에 훨씬 깔끔합니다.

0.1. 동적 배열
사용자로부터 배열의 크기를 입력받아서 배열을 만들고 싶을 때가 있을 수 있습니다.
하지만 배열은 컴파일 타임에 크기를 결정하기 때문에, 사용자로부터 크기를 받아서 배열을 만드려고 하면 상수가 아니라고 하면서 컴파일 에러가 발생하고 맙니다.

이런 문제를 해결하기 위해서는 동적 배열을 사용하면 됩니다.
new[] 연산자와 delete[] 연산자를 통해 실행 시간에 배열의 길이를 선택할 수 있게 됩니다.
다만 new[]로 만든 동적 배열의 경우 반드시 delete[]로 지워주어야 합니다.
컴파일 시간에 만든 요소가 아닌 실행 시간에 사용자가 직접 만든 동적 배열이기 때문에 컴파일러는 프로그램이 끝나도 이 배열을 따로 지우지 않습니다.
만약 지우지 않으면 메모리가 낭비되겠죠?
아래 예시에서는 사용자로부터 3이라는 크기를 받아서 3 크기의 배열을 만들었습니다.
배열에 2 4 6이라는 요소를 넣었고 순서대로 출력했습니다.
그리고 마지막에 delete[]를 통해서 메모리 할당을 해제했습니다!
(TMI : 일반적인 요소는 stack이라는 저장소에 저장되고, 동적으로 만든 요소는 heap이라는 저장소에 저장됩니다!)

0.2. 배열 복사
for문, 혹은 while문을 이용하여 요소를 직접 가져와서 복사할 수 있습니다.
대신 이렇게 복사할 경우 배열을 미리 선언하고 복사해야 합니다.
b = a와 같은 형식으로 복사할 수 없습니다.

0.3. 다차원 배열
배열 안에 배열이 들어가는 것을 다차원 배열이라고 합니다.
이렇게 배열이 여러 개 겹쳐있다면, 접근할 때도 괄호를 여러 번 사용해서 접근해야 합니다.
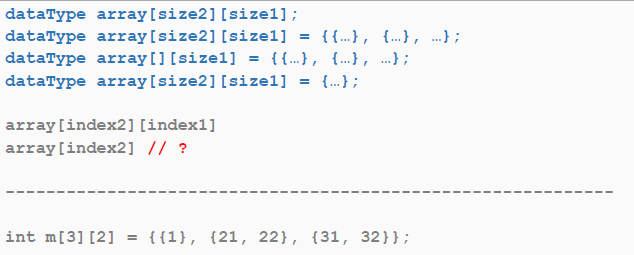
다차원 배열의 요소에 직접 접근하는 예시입니다.
a[1]로 접근할 때 {2,3}이 아닌 주소값이 나오는 이유가 궁금할 수 있습니다.
인덱스 없이 배열의 이름만 쓰면 그 배열의 주소값을 가리킨다고 했었죠?
바로 그 원칙이 그대로 적용되어서, a[1]은 {2,3}의 주소값을 가리키게 됩니다.

0. Vector
벡터(Vector)는 요소들을 순차적으로 저장할 수 있는 컨테이너입니다.
벡터는 C++의 STL(Standard Template Library)중 하나입니다.
이미 만들어진 라이브러리에서 쉽게 가져다 사용할 수 있죠.
그렇기 때문에 사용하기 위해서는 전처리 과정에서 #include <vector>를 통해 라이브러리를 불러와야 합니다.
벡터는 namespace 내부에서 사용해야 하기 때문에 std::를 붙여주거나 전처리문 아래에 using namespace std;를 써서 std::를 생략할 수 있습니다.
vector<자료형> 벡터명(크기, 초기화값)
vector<자료형> 벡터명{요소1, 요소2, ...)
와 같은 형식으로 사용할 수 있습니다.
그리고 벡터의 요소에 접근할 때도 배열과 똑같이 벡터명[인덱스]를 통해 접근할 수 있습니다.

또한 동적인 특성을 가지고 있기 때문에 벡터의 크기는 계속해서 변할 수 있습니다.
push_back, pop_back 등을 통해 요소를 넣거나 뺄 수 있습니다.
vector 자료형에서 사용할 수 있는 함수들은 아래와 같습니다.

push_back을 통해 추가하고, pop_back을 통해 빼고, size를 통해 크기를 구하고, at을 통해 벡터에 접근하고, []를 통해 벡터에 접근하는 예시를 보실 수 있습니다.

for문을 이용하여 vector의 요소를 가져다 쓸 때 : 를 사용해서 보다 편리하게 요소를 넣고, 추출할 수도 있습니다.
입력을 받을 때 &를 통해 주소값에 입력해 주는 것을 잊지 마세요!

벡터 역시 다차원으로 만들 수 있습니다.
다차원으로 만들면 접근도 똑같이 []를 여러 번 사용함으로써 가능합니다.

이번 포스팅에서는 배열과 벡터의 개념과 기본 사용법에 대해서 알아봤습니다.
이제 여러 데이터를 동시에 다룰 수도 있게 되었네요 :)
다음 포스팅에서는 연속적인 데이터를 가공하는 방법에 대해서 알아보도록 하겠습니다!
오늘도 읽어주셔서 감사합니다 :)








최근댓글