전 포스팅에서 트리를 배웠으니, 트리를 이용한 자료구조를 하나 배워보도록 하겠습니다!
최댓값과 최솟값을 구하는 데에 있어서 가장 핵심적인 자료구조인 힙과 힙이 가장 많이 쓰이는 우선순위큐에 대해서 알아봅시다!
목차
0. 힙 (Heap)
이름부터 심상치 않죠? Heap이라니... 도대체 왜 이런 이름이 붙었을까요?
현실 세계에서 Heap은 아래 사진과 같은 더미를 뜻합니다.

자료구조의 Heap은 이와 비슷하게 트리 형태로 쌓인 데이터를 의미합니다. 나름 비슷하게 생겼죠?!!

힙은 최댓값이나 최솟값을 빠르게 찾기 위해 만들어진 자료구조입니다.
트리구조, 그 중에서도 완전 이진 트리 형태를 가지고 있습니다.
생긴건 저렇게 생겨먹었는데, 어떻게 최댓값이나 최솟값을 빠르게 찾을 수 있을까요?
힙은 맨 위에 있는 루트노드에 항상 최댓값이나 최솟값이 위치하는 자료구조입니다.
따라서 최댓값과 최솟값을 O(1) 안에 찾을 수 있는 것이죠.
부모 노드와 자식 노드의 키값 사이에는 대소관계가 존재합니다.
최댓값이 꼭지점에 위치한 Max-Heap의 경우 부모 노드의 키값이 반드시 자식 노드의 키값보다 큽니다.
반대로 최솟값이 꼭지점에 위치한 Min-Heap의 경우 부모 노드의 키값이 반드시 자식 노드의 키값보다 작습니다.
그렇다면 어떤 방식으로 항상 꼭짓점에 있는 요소가 최댓값 혹은 최솟값이 되는 것일까요?
데이터의 삽입과 삭제 과정을 살펴보면 쉽게 이해할 수 있습니다.
0.0. 데이터 삽입
삽입은 완전 이진 트리의 맨 마지막 노드에 이루어집니다.
그 후 부모 노드와 서로 비교한 후에 적절한 위치가 아니라면 서로의 위치를 바꿉니다.
이 과정을 적절한 위치에 도달할 때까지 반복하는 것이죠.
이 과정을 reHeapUp이라고도 부릅니다.

0.1. 데이터 삭제
삭제는 먼저 루트 노드를 제거하는 것부터 시작합니다.
그 이후 완전 이진 트리의 마지막 노드를 루트 노드로 옮깁니다.
이제 자식 노드들과 서로 비교한 후에 적절한 위치가 아니라면 서로의 위치를 바꿉니다.
이 과정을 적절한 위치에 도달할 때까지 반복하면 됩니다!
이 과정을 reHeapDown이라고도 부릅니다.

1. 우선순위 큐 (Priority Queue)
우선순위 큐는 데이터에 우선순위를 부여하여 들어간 순서와 관계 없이 우선순위가 높은 데이터가 먼저 나오게 되는 큐를 의미합니다.
대부분의 경우 Heap을 이용하여 우선순위 큐를 만듭니다.
그렇다고 다른 자료구조를 이용해서 우선순위 큐를 구현하는 것이 불가능하다는 이야기는 아닙니다.
우선순위 큐를 만들기 위해 가장 효율적인 자료구조가 Heap이기 때문에 Heap을 사용할 뿐이죠.
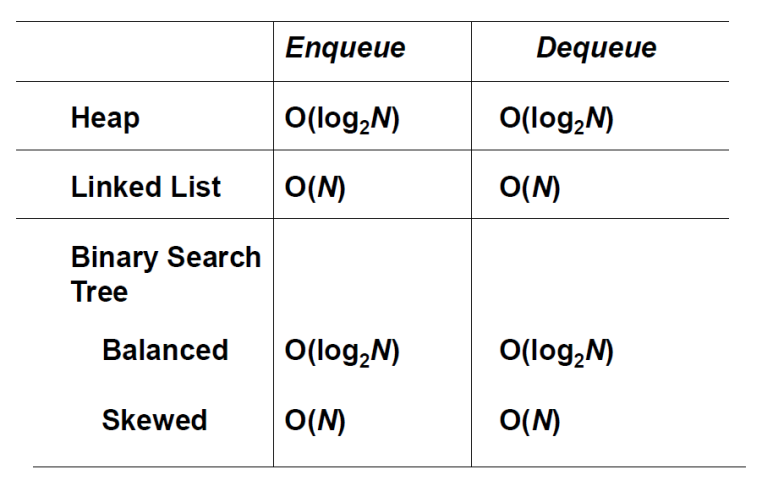
각종 자료구조를 이용하여 우선순위큐를 만들게 된다면 어떤 시간복잡도가 나오는지에 대해서 간략하게 알아봅시다!
- Array - 최댓값 혹은 최솟값을 찾는데 O(n), 빼면 최악의 경우 O(N)만큼 shift 해야합니다.
- 삽입과 삭제시 O(n)!!
- Linked List - 정렬이 되어있지 않다면 최댓값 혹은 최솟값을 찾기 위해서 모든 요소를 거쳐야 합니다. (그나마 빼고 넣는데 시간은 O(1)이네요!)
- 삽입과 삭제시 최악의 경우 O(n)!!!
- Binary Search Tree - 한쪽으로 쏠린 이진 탐색 트리의 경우 최악의 경우 모든 요소를 거쳐야 합니다.
- 삽입과 삭제시 최악의 경우 O(n)!!!
- Heap - 완전 이진 트리이기 때문에 삽입 삭제시 O(logN)을 보장합니다.
- 최악의 경우에도 O(logN)!!!








최근댓글