오늘 배울 내용은 데이터의 기초가 되는 변수와 데이터형입니다.
이번 포스팅이 끝날 때 쯤이면 변수를 어떻게 선언하고 그 변수들의 형태에 대해 이해하실 수 있을 겁니다 ㅎㅎ
목차
0. 변수와 상수
변수는 값이 변경될 수 있는 데이터이고, 상수는 값이 변경될 수 없는 데이터입니다.
변수와 상수는 모두 데이터를 보관해 둘 필요가 있을 때 사용합니다.
값이 변경될 것 같으면 변수를 쓰고, 변경되서는 안되는 경우에는 상수를 쓰면 되겠죠?

변경될 수 있는 데이터들은 메모리에 보관합니다.
메모리는 연속된 데이터 바이트의 모임을 말하며, 메모리의 각 바이트는 주소를 가집니다.
어떤 변수를 바꾼다고 하면, 그 변수의 주소를 찾아가서 거기서부터 내용들을 하나하나 덮어씌우게 됩니다.
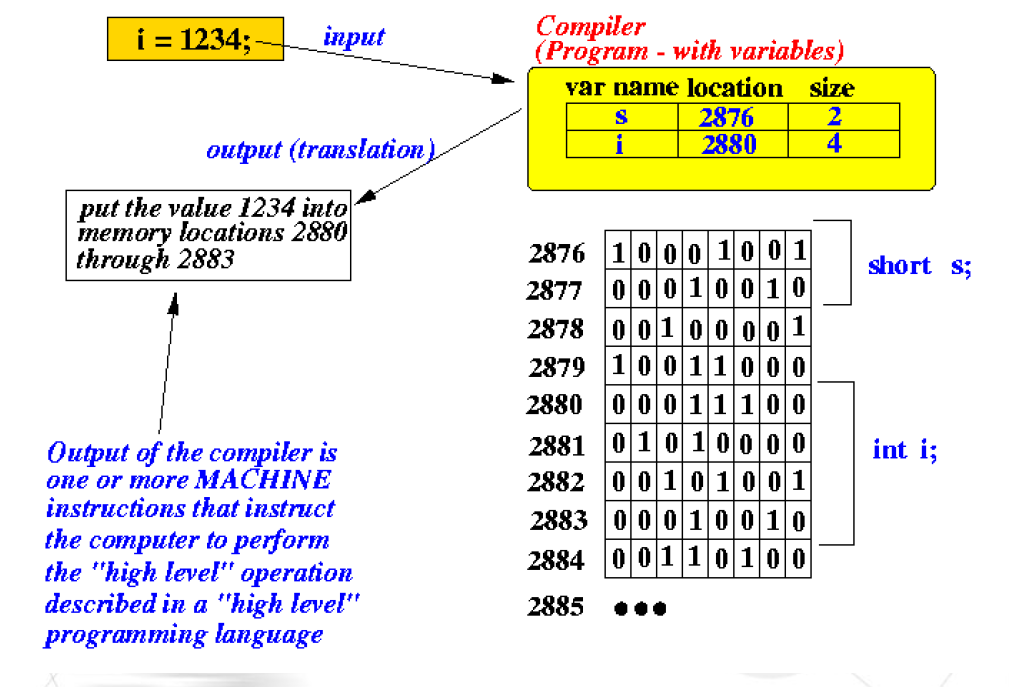
위 그림에서 오른쪽의 표에 short와 int가 있는데, 각각 2개의 메모리와 4개의 메모리를 사용합니다.
이처럼 메모리에 저장할 데이터 값의 형식(type)에 따라 메모리가 얼마만큼 필요한 지가 결정됩니다.

변수가 뭔지 알았으니, 변수를 선언하는 방법에 대해서도 알아봅시다.
변수를 사용하기 위해 특정 크기의 메모리를 준비하는 것을 '변수에 메모리를 할당한다' 라고 합니다.
메모리에 저장될 값의 데이터형에 따라 필요한 만큼 데이터를 할당하는 것이죠.
선언을 할 때는 앞쪽에는 데이터형, 뒷쪽에는 변수 이름을 작성하면 됩니다.

이렇게 변수를 선언하고 나면 선언한 변수를 사용해야겠죠?
위에서 데이터형 옆에 변수의 이름을 설정했는데, 이 이름을 이용하면 메모리에 접근할 수 있습니다.
각 이름마다 주소가 지정되어서 이름을 가져올 때마다 주소값도 같이 불러오게 되는 것이죠.
이름 = 데이터
형태를 통해서 변수에 값을 저장할 수 있고, printf("%데이터형", 이름); 형태로 변수의 값을 읽어올 수 있습니다.


각 데이터 형마다 다른 크기값을 가지고 있습니다. char는 1바이트, short는 2바이트, int는 4바이트, long는 8바이트 등입니다. 아래 표를 참고하세요!

이번엔 식별자에 대해서 알아보겠습니다.
식별자는 변수를 구분하기 위해서 사용되는 이름입니다.
이 이름을 막 지을 수 있다면 참 좋겠지만, 컴퓨터가 보다 명확하게 알아들을 수 있도록 특수한 규칙이 존재합니다.
※ 식별자의 규칙
- 식별자는 반드시 영문자, 숫자, 밑줄 기호( _ )만을 사용해야 합니다.
- 식별자의 첫 글자는 반드시 영문자 또는 밑줄 기호( _ )로 시작해야 합니다. (숫자로 시작할 수 없습니다)
- 식별자에는 밑줄 기호( _ )를 제외한 다른 기호를 사용할 수 없습니다.
- 식별자는 대소문자를 구분합니다. (n과 N은 다릅니다. 컴퓨터는 ASCII코드를 참고하기 때문입니다!!)
- C언어의 키워드는 식별자로 사용할 수 없습니다. 키워드는 C 언어 자체에서 사용하기 위해 이미 설정해 놓은 이름입니다.

1. 변수와 상수의 선언
내용이 길어질 것 같아서 변수와 상수 부분을 둘로 나누었습니다.
변수의 선언에 대해서 위에서 간략하게 살펴봤다면, 이번에는 보다 자세하게 실제로 변수와 상수를 선언하는 과정에 대해 알아보겠습니다.
변수를 선언할 때는 위에서 공부했던 식별자의 규칙에 맞춰서 선언해야 합니다.
아래 사진은 공부했던 내용에 대한 복습입니다!

또한, 변수의 선언문은 선언한 변수를 이용하는 다른 모든 문장보다 앞쪽에 위치해야 합니다.
선언도 안했는데 사용할 수는 없겠죠?

변수의 값을 읽어오거나 저장하기 위해서는 변수명을 이용하고, 변수에 값을 저장하기 위해서는 대입연산자(=)를 이용합니다. 이 부분도 위에서 살짝 언급했던 부분입니다!

만약 변수를 선언할 때 값을 저장하지 않는다면 어떻게 될까요?
어떤 값이 메모리에 들어있을 지 알 수 없기 때문에 쓰레기 값이 들어있습니다.
이게 진짜 쓰레기라고 해서 진짜 "Garbage"가 들어있는게 아니라 이상한 숫자값이 들어있습니다.
값을 담기 위해 만든 변수/상수인데 값을 담지 않으면 그 안에 이미 존재하고 있던 값은 필요가 없는 값이겠죠?
그런 의미로 쓰레기값이라고 부릅니다.
그리고 이렇게 변수가 처음 메모리에 할당될 때 값을 지정하는 것을 변수의 초기화라고 합니다.
앞으로는 변수를 설정하고 처음에 값을 할당할 때 초기화라는 표현을 사용할 예정이니 꼭 기억해두도록 합시다.

위 내용을 종합해서 실제로 변수의 초기화 과정을 구현하면 아래와 같습니다.

이번엔 리터럴에 대해서 알아보겠습니다.
리터럴은 변수에 넣는 변하지 않는 데이터를 의미합니다.
상수와는 조금 다른데, 상수는 변하지 않는 수(메모리 위치)를 의미하고, 리터럴은 변수와 상수에 들어가는 고정된 값(메모리 위치 안의 값)을 의미합니다. 조금 다르죠?


이렇게 변수/상수를 만들어서 초기화까지 해줬으면 출력도 할 수 있어야겠죠?
printf 함수 내에는 변수/상수 이름도 들어가지만, 그 앞에 이상한 %가 들어가기도 합니다.
이 위치에는 형식 문자열이 들어갑니다. 지정한 형식 문자열이 출력된다는 이야기입니다.
이 %로 시작하는 형식문자열은 " " 따옴표 안에 들어가도 상관이 없어서 편리하게 사용할 수 있습니다.

이번엔 매크로 상수에 대해서 알아보겠습니다.
매크로 상수는 일반적인 상수와 다르게 #define문으로 정의되는 상수를 뜻합니다.
#define 매크로명 값
형태로 사용할 수 있으며, #가 앞에 붙어있는 것을 보면 쉽게 전처리문인 것을 알 수 있습니다. 전처리 과정에서 처리되는 것이죠.
C 언어 문장이 아닌 전처리문이기 때문에 세미콜론이 필요가 없는 것이 특징입니다.
또한 매크로 상수의 값은 컴파일 시간이나 실행 시간에 변경할 수 없습니다.


정리하면 매크로 상수의 #define는 매크로 상수를 특정 값으로 바꿔줍니다.

리터럴과 매크로 상수에 대해서 살펴봤으니 이제 일반 상수에 대해서도 알아봅시다.
변수를 선언할 때 데이터형 앞에 const를 적으면 값을 변경할 수 없는 변수가 됩니다.
const가 압정이라고 생각하시면 됩니다. 값을 바꿀 수 없게 압정 혹은 못을 박아버린거에요.
그리고 const 변수는 반드시 선언할 때 초기화해야 한다는 특징을 가지고 있습니다.


상수에 이름을 부여하면 이것을 기호 상수라고 부릅니다.
리터럴을 사용하는 것에 비해 기호 상수의 장점은 프로그램을 수정하기 쉬워지고, 프로그램의 가독성이 향상됩니다.

정리하면 상수에는 리터럴, 매크로 상수, const 변수가 있습니다.
리터럴 : 'A', 10, 3.14
매크로 상수 : #define MAX 100
const 변수 : const int max = 100;
2. 데이터형
C 프로그램에서 사용되는 모든 변수나 상수 값은 정해진 데이터형을 가집니다.
데이터형에 의해서 주어진 값의 이진 표현이 결정되는 것이죠.
데이터형은 기본 데이터형, 파생 데이터형, 사용자 정의형 총 세 가지로 나눠집니다.
기본 데이터형은 이미 존재하는 문자형(char), 정수형(short, int, long), 실수형(float, double)을 뜻하고,
파생 데이터형은 배열과 포인터를 뜻하고,
사용자 정의형은 구조체, 공용체, 열거체 등을 뜻합니다. 사용자 정의형은 직접 정의하는 것이라고 생각하면 됩니다.
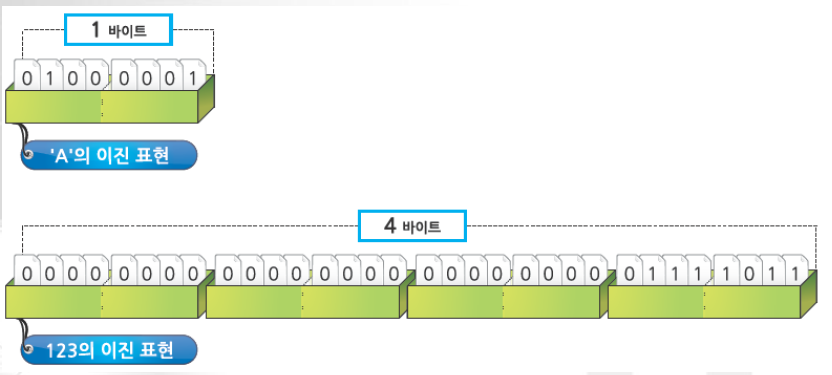
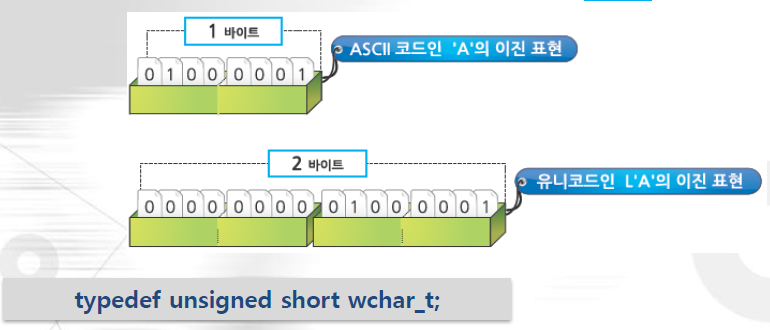
문자형(char)은 1바이트 크기의 데이터형으로, 문자코드를 저장합니다.
문자코드는 대표적으로 ASCII 코드가 있습니다.
이 중에서 ASCII 코드 중에서도 특별한 용도로 사용되는 특수 문자가 있는데, 이 특수 문자는 '\' 혹은 백슬래쉬와 함께 나타납니다.




ASCII 코드 이외에도 문자코드로 쓰이는 멀티바이트 문자집합(MBCS), 유니코드 등이 있습니다.
MBCS는 한 문자를 여러 바이트로 표현합니다. 영문자는 1바이트, 한글은 2바이트로 표현하죠.
유니코드는 한글과 영문 모두 한 글자를 2바이트로 표현합니다. 이 때는 char형 대신 wchar_t형을 사용합니다.
정수형은 정수를 다루는 데이터형입니다. C언어는 기본적으로 short, int, long을 제공합니다.
크기 순서는 short < int < long입니다.
그리고 정수형은 signed형과 unsigned형으로 나누어지며, signed는 생략할 수 있습니다.
signed는 부호가 존재하고(음수가 존재) unsigned는 부호가 존재하지 않습니다. 따라서 signed의 숫자 범위와 unsigned의 숫자 범위에는 차이가 나게 됩니다.
부호를 저장하는 방법은 메모리의 맨 첫 비트를 부호비트로 할당하여 0이면 양수, 1이면 음수로 처리합니다.
만약 이 자리에 숫자 데이터가 들어가게 되면 unsigned가 되는 것이죠.
또한 signed형의 경우 음수를 표현하는 데 2의 보수를 사용합니다.
보수에 대한 내용은 너무 길어질 수 있으니 아래 위키주소로 대체합니다.
2의 보수 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 2의 보수(--補數, 영어: two's complement)란 어떤 수를 커다란 2의 제곱수에서 빼서 얻은 이진수이다. 2의 보수는 대부분의 산술연산에서 원래 숫자의 음수처럼 취급
ko.wikipedia.org



만약 유효 범위에서 벗어나는 수를 변수에 넣으려고 하면 오버플로우 혹은 언더플로우가 발생합니다.
이 경우 해당 데이터형의 유효범위 내의 값으로 설정됩니다.
어떻게 되든 원하는 값이 아니기 때문에 좋지 않은 현상이죠.

실수형은 고정소수점(fixed point) 방식과 부동소수점(floating point)방식이 있습니다.
보통은 부동소수점(floating point)방식을 주로 사용합니다.
부동소수점 방식이 더 많은 수를 표현할 수 있기 때문입니다.


대신 이런 부동소수점 방식의 경우 정확한 숫자를 담는 것이 아니기 때문에 오차가 발생할 수 있습니다.

위 내용에 대해 보다 자세하게 알고 싶으신 분은 아래 링크를 참조하세요!
C 언어 코딩 도장: 85.4 실수 자료형의 오차
부동소수점 방식은 실수를 정확히 표현할 수 없는 문제가 있습니다. 다음 내용을 소스 코드 편집 창에 입력하고 실행해봅니다. float_rounding_error.c #include int main() { float num1 = 0.0f; float num2 = 0.1f; // 0
dojang.io
마지막으로 sizeof 연산자에 대해서 알아보겠습니다.
sizeof 연산자는 주어진 값이나 데이터형의 바이트 크기를 구합니다.



오늘 포스팅에서는 이것저것 다 적다보니 양이 너무 길어진 면이 있습니다..
다음 포스팅부터는 내용을 조금 더 압축하도록 노력하겠습니다 ㅠㅠ
위 내용을 모두 이해하지 못했다고 하더라도 괜찮습니다. 너무 양이 많아서..
계속 진행하시다보면 충분히 이해하실 수 있으니 자신감을 가지고 계속 공부하시면 됩니다 :)
그렇다면 다음 포스팅에서 뵙도록 하겠습니다!








최근댓글