원래는 하나의 포스팅으로 계획했으나, 내용이 너무 길어져서 이렇게 따로 뒷 부분을 분리하게 되었습니다.
이전 시간에 간단한 알고리즘에 대해서 알아봤다면, 이번 시간에는 알고리즘의 성능을 판단하는 시간복잡도와 공간복잡도에 대해서 간단하게 알아보도록 하겠습니다.
목차
0. 알고리즘의 분석
우선 공간복잡도는 입력크기에 따라서 작업공간(메모리)이 얼마나 필요한지를 결정하는 절차입니다.
그리고 시간복잡도는 입력크기에 따라서 단위연산이 몇 번 수행되는지 결정하는 절차입니다.
현대 시대에 와서는 공간은 넉넉하기 떄문에 공간복잡도보다는 시간복잡도에 더 큰 관심을 가지는 경우가 많습니다.
시간복잡도 분석은 보통 단위연산(비교문, 지정문), 혹은 입력크기(배열의 크기, 리스트의 길이, 행과 열의 크기, 트리의 마디와 이음선의 수)등으로 할 수 있습니다.
또한, 분석 방법에 따라 모든 경우 분석, 최악의 경우 분석, 평균의 경우 분석, 최고의 경우 분석으로 나뉘는데, 보통 최악의 경우 분석을 사용합니다. 아무래도 최악의 경우를 대비해야 하기 때문입니다.
그렇다면 이전 포스팅에서 알아봤던 간단한 알고리즘으로 직접 확인해봅시다.

# 모든 경우 분석 - 배열 내용에 상관 없이 for 루프가 n번 반복된다. 따라서 덧셈이 수행되는 횟수는 T(n) = n 이다.
def sum(n,s):
result = 0
for i in range(n):
result += s[i]
return result
n = 3
s = [1,3,5]
print(sum(n,s))

# 모든 경우 분석 - for문을 2번 사용했기 때문에 조금 복잡하지만, 계산해보면 (n-1)n/2만큼을 수행한다.
s = [3,2,5,7,1,9,4,6,8]
n = len(s)
for i in range (0,n-1):
for j in range(i+1,n):
if(s[i] > s[j]):
s[i],s[j]=s[j],s[i]
print(s)

# 모든 경우 분석 - for문이 각각 n번씩 수행되는데, 3번에 걸쳐서 진행되므로 T(n) = n^3
def matrix_multiplication(a,b):
c = [[0 for i in range(len(b[0]))] for j in range(len(a))]
for i in range(len(a)):
for j in range(len(b[0])):
for k in range(len(a[0])):
c[i][j] = c[i][j] + a[i][k] * b[k][j]
return c
a=[[1,2],[3,4]]
b=[[4,1],[1,0]]
print(matrix_multiplication(a,b))

# 최악 경우 분석 - 연산은 x가 배열 마지막인 경우 최대 n번 수행! W(n) = n
# 최선 경우 분석 - x가 s의 맨 앞에 있다면 1번만에 찾을 수 있다! B(n) = 1
# 평균 경우 분석 - 배열의 아이템이 모두 다르다고 가정하고,
# 1. x가 배열 S 안에 있는 경우 x가 배열의 k번째 있을 확률은 1/n입니다.
# k번째에 있는 x를 찾기 위해서는 k번 연산해야 합니다.
# 즉, A(n) = 시그마(k=1, n) k/n = (n+1)/2
# 2. x가 배열 S 안에 없는 경우
# x가 k번째 있을 확률 p/n, x가 배열에 없을 확률 1-p
# A(n) = 시그마(k=1, n) {(k*p/n) + n(1-p)} = n(1-p/2)+p/2가 됩니다.
def seqsearch(s,x):
location = 0
while location < len(s) and s[location] != x:
location = location+1
if (location == len(s)):
location = -1
return location
s = [3,5,2,1,7,9]
loc = seqsearch(s,4)
print(loc)
++ 정확도 분석은 알고리즘이 의도한 대로 수행되는지를 증명하는 절차입니다.
어떠한 입력에 대해서도 답을 출력하면서 멈추는 알고리즘이 정확한 알고리즘인데, 이것을 증명하는 것은 쉽지 않습니다.
1. 복잡도 함수
복잡도 함수를 알아보기 전에, 복잡도 함수에 들어가는 매개변수는 다양합니다. 그 중에서도 차수가 높은 변수가 궁극적으로 지배하게 됩니다.
이 말은 만약 n이 무한대로 늘어난다면 n번씩 반복하는 것을 상수번만큼 반복한다고 해서 n^2보다 많이 수행할 수는 없다는 것을 의미합니다.
이것은 아래 증가율 그래프를 보시면 더욱 명확하게 확인하실 수 있습니다.


이제 복잡도 함수의 다양한 표기법에 대해 알아보겠습니다.
대표적으로 5가지 종류가 있으며, 가장 많이 쓰는 것이 맨 위에 있는 Big-O notation입니다.

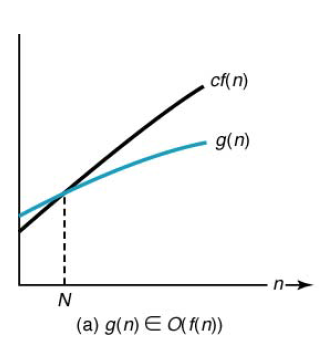
1.0. Big-O (점근적 상한)
big-O는 점근적 상한으로, 복잡도 함수 f(n)에 대해 g(n)∈Ο(f(n))이면 n>N인 모든 정수 n에 대해서 0≤g(n) ≤c×f(n)이 성립하는 양의 실수 c와 음이 아닌 정수 N이 존재하게 됩니다.
g(n)이 O(n^2)에 속한다면, n이 커짐에 따라 어떤 이차 함수 cn^2보다는 작은 값을 가지게 된다는 말입니다. 이 말은 g(n)은 어떤 이차 함수 cn^2보다는 궁극적으로 좋다고 말할 수 있습니다.

1.1. Ω(점근적 하한)
오메가는 점근적 하한으로, 복잡도 함수 f(n)에 대해 g(n) ∈Ω(f(n))이라면 n>N인 모든 정수 n에 대해서 g(n) ≥c*f(n) ≥0이 성립하는 양의 실수 c와 음이 아닌 정수 N이 존재하게 됩니다.


1.2. Θ(차수)
Θ는 Θ(f(n))= O(f(n))∩ Ω(f(n))로 정의할 수 있습니다.
g(n)∈Θ(f(n))을 다른 말로 하면 g(n)은 f(n)의 차수(order)라고 할 수 있습니다.



1.3. small-O
주어진 복잡도 함수 f(n)에 대해서 g(n) ∈o(f(n))이면 모든 양의 실수 c에 대해, n≥N인 모든 n에 대해서 0≤ g(n)≤c×f(n) 이 성립하는 음이 아닌 정수 N이 존재합니다. 이 말은, g(n)이 f(n)에 비해 차수가 하나 이상 더 적어야 한다는 말과 같죠.
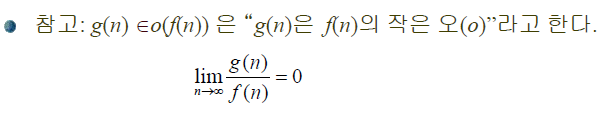
1.4. ω(small omega)
복잡도 함수 f(n)에 대해 g(n) ∈Ω(f(n))이라면 모든 양의 실수 c에 대해 n>N인 모든 정수 n에 대해서 g(n) ≥c*f(n) ≥0이 성립하는 양의 실수 c와 음이 아닌 정수 N이 존재하게 됩니다. g(n)이 f(n)에 비해 차수가 하나 이상 더 많아야 한다는 말과 같죠.

이 복잡도 함수와 차수의 주요 성질은 아래와 같습니다.
- 0. g(n)∈O(f(n)) if and only if f(n)∈Ω(g(n))
- 1. g(n)∈Θ(f(n))if and only if f(n)∈Θ(g(n))
- 2. 로그 복잡도 함수는 모두 같은 카테고리에 속한다
- 3. 지수 복잡도 함수는 모두 같은 카테고리 안에 있는 것은 아니다
- 4. a>0인 모든 a에 대해서 a^n ∈ o(n!) 이다. 즉 n!은 어떤 지수 복잡도보다 나쁘다
- 5. 복잡도 함수의 순서는 아래와 같다 (k>j>2, b>a>1)

- 6. big-O를 이용한 차수계산은 아래와 같다








최근댓글